


Visual RAG over PDFs with Vespa - A demo application in Python
Introduction
Thomas joined Vespa as a Senior Software Engineer in April 2024. His last assignment in his previous role as an AI consultant was actually to build a RAG application over a large collection of PDFs using Vespa.
PDFs are ubiquitous in the enterprise world, and the ability to search and retrieve information from them is a common use case. The challenge is that many PDFs often belong to one or more of the following categories:
- They are scanned documents, which mean the text is not easily extractable, and one must resort to OCR, which adds complexity.
- They contain a lot of charts, tables, and diagrams, which are not easily searchable, even if the text is extractable.
- They contain a lot of images, which sometims contain valuable information.
Note that the term ColPali is overloaded to mean two things:
- A particular model with a corresponding paper1 that trains a LoRa-adapter on top of a VLM (PaliGemma) to generate joint embeddings for text and images (one embedding per patch in the image) to be used for “late interaction”, building upon the ColBERT approach to vision language models.
- It also represents a direction in visual document retrieval, combining the power of VLMs with efficient late interaction mechanisms. This direction is not limited to the specific model in the original paper, but can be applied to other VLMs, see for instance our notebook on using ColQwen2 with Vespa2.
In this blog post, we will do a deep dive into the process of building a live demo application showcasing Visual RAG over PDFs using ColPali embeddings in Vespa. We will describe the architecture, user experience, and the tech stack used to build the application.
Here are some screenshots from the demo application:
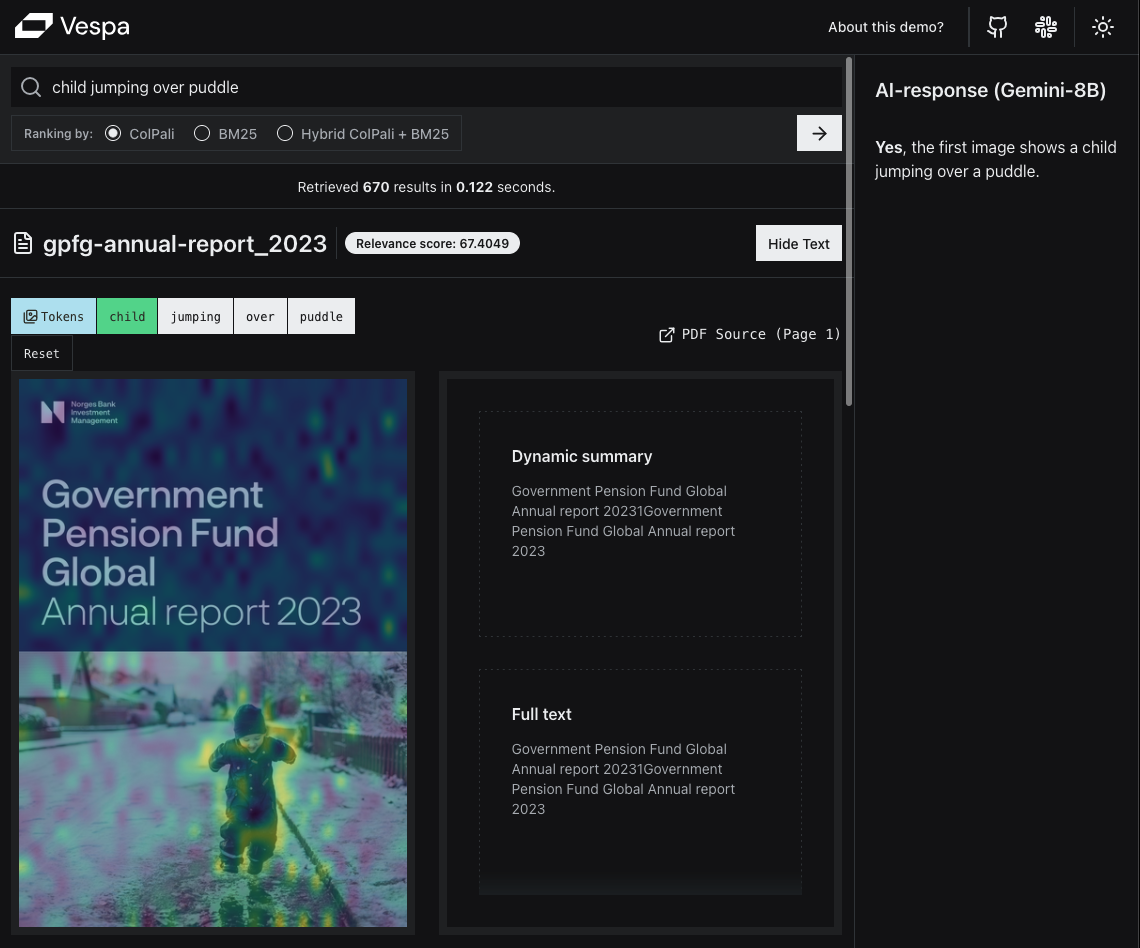
Our first example is not a likely query, but illustrates the power of Visual Retrieval for some types of queries. This is a good illustration of the “WYSIWYS” (What You See Is What You Search) paradigm.
The similarity map that highlights the most similar patches makes it easy to see which parts of the page are most similar to the query.
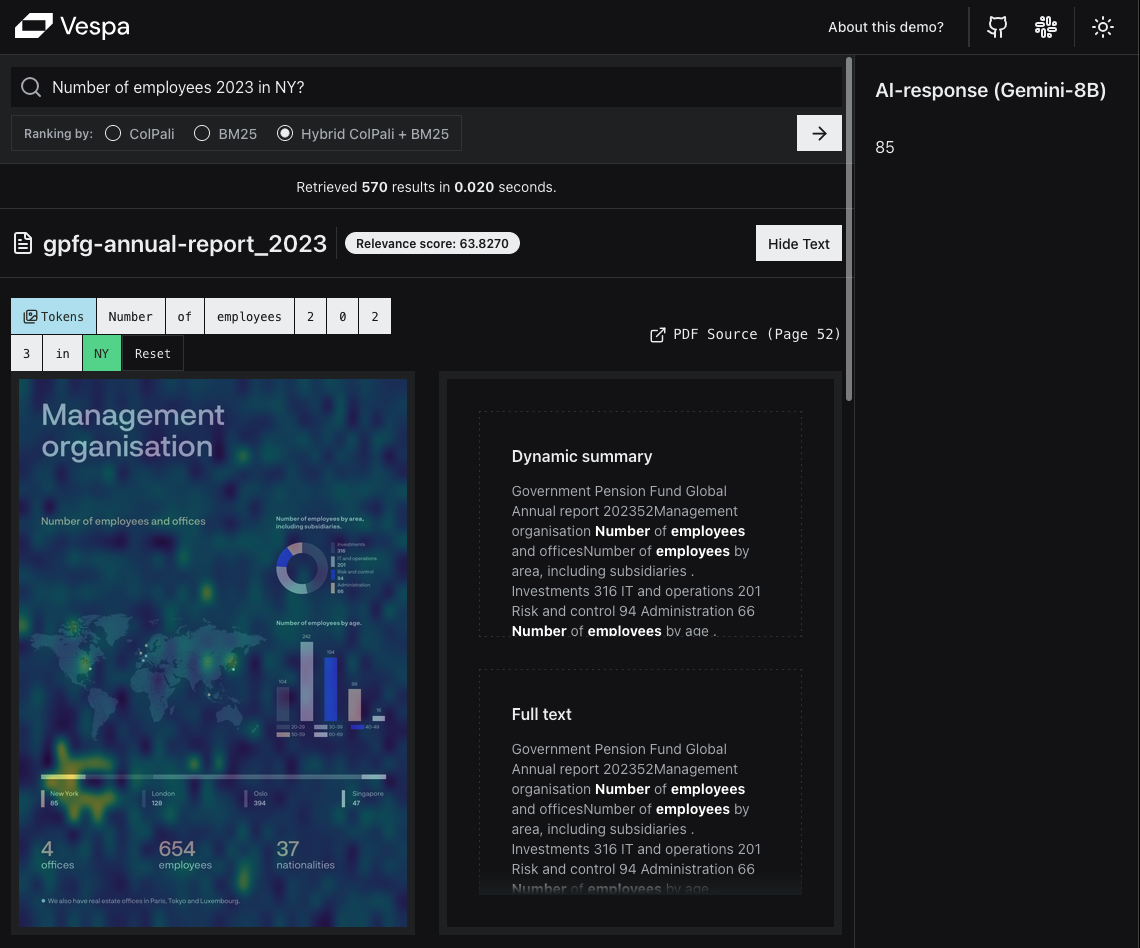
Our second example is a more likely user query, and illustrates the power of ColPali for semantic similarity,
Having experienced the struggle of making PDF’s searchable first hand, the latest advancements in the field of Vision Language Models (VLMs) has been a particular area of interest for Thomas.
After reading the previous Vespa blog posts on ColPali, as well as participating in engaging discussions with Jo Bergum, he was inspired to propose a project to build a Visual RAG application over PDFs using Vespa.
At Vespa, everyone has the opportunity to propose work packages they would like to work on every sprint. As long as the suggested work is aligned with the company’s goals, and there are no other urgent priorities, we get to work on it. For Thomas, coming from a consulting background, this kind of autonomy is a breath of fresh air.
TL;DR
We built a live demo application showcasing Visual RAG over PDFs using ColPali embeddings in Vespa using Python only, with FastHTML at the center.
We also provide the code for you to replicate it:
- A notebook you can run to set up your own Vespa application for Visual RAG.
- The code for the FastHTML app that you can use to set up a web app that interacts with the Vespa application.
The task
The purpose of the project was twofold:
1. Build a live demo
We developers might be impressed by a demo with JSON-output in terminal as the UI, but believe it or not, most people prefer a web interface.

This would enable us to showcase Visual RAG over PDFs using ColPali embeddings in Vespa. We see this as relevant across many use cases and industries, such as legal, finance, construction, academia and healthcare.
We feel confident that this will be very relevant going forward, but we have not seen any live applications that demonstrate this in practice.
This would also provide us a lot of valuable insights with regards to efficiency, scalability and user experience. We were also curious (or should we say anxious) to find out whether it would be fast enough to provide a good user experience.
We also wanted to highlight a few useful Vespa features, such as:
- Phased ranking
- Type-ahead suggestions
- Multivector MaxSim-calculations
2. Create an open source template
We wanted to provide a template that others can build upon to create their own Visual RAG applications.
The template should be easy for others to copy, and not require a plethora of specific programming languages or frameworks.
Creating the dataset
For our demo, we wanted to use a dataset of PDF documents where a significant amount of relevant information is contained in images, tables and diagrams. We also wanted to use a dataset of a size large enough to illustrate the unfeasibility of just uploading all images directly to a VLM (skipping the retrieval step).
With gemini-1.5-flash-8b, the current maximum input images is 3600.
We found no public dataset that met our requirements, so we decided to create our own dataset.
As proud Norwegians, we were happy to discover that our Government Pension Fund Global (GPFG, also known as the Oil Fund) has published their annual reports and governing documents since 2000 on their website. With no mention of copyright on the website, and their recent announcement of being the world’s most transparent fund, we felt confident that we could use this data for our demo.
The dataset consists of 6992 pages from 116 different PDF reports dating from 2000 to 2024.
The dataset, including images, text, url, page_no, generated questions, queries, and ColPali embeddings, is available here.
Generating synthetic queries and questions
We also decided to generate synthetic queries and questions for each page. These could serve two purposes:
- We could use them to provide type-ahead suggestions in the search bar as a user types.
- We could use them for evaluation purposes.
The prompt we used to generate questions and queries was inspired by this wonderful blog post by Daniel van Strien.
You are an investor, stock analyst and financial expert. You will be presented an image of a document page from a report published by the Norwegian Government Pension Fund Global (GPFG). The report may be annual or quarterly reports, or policy reports, on topics such as responsible investment, risk etc.
Your task is to generate retrieval queries and questions that you would use to retrieve this document (or ask based on this document) in a large corpus.
Please generate 3 different types of retrieval queries and questions.
A retrieval query is a keyword based query, made up of 2-5 words, that you would type into a search engine to find this document.
A question is a natural language question that you would ask, for which the document contains the answer.
The queries should be of the following types:
1. A broad topical query: This should cover the main subject of the document.
2. A specific detail query: This should cover a specific detail or aspect of the document.
3. A visual element query: This should cover a visual element of the document, such as a chart, graph, or image.
Important guidelines:
- Ensure the queries are relevant for retrieval tasks, not just describing the page content.
- Use a fact-based natural language style for the questions.
- Frame the queries as if someone is searching for this document in a large corpus.
- Make the queries diverse and representative of different search strategies.
Format your response as a JSON object with the structure of the following example:
{
"broad_topical_question": "What was the Responsible Investment Policy in 2019?",
"broad_topical_query": "responsible investment policy 2019",
"specific_detail_question": "What is the percentage of investments in renewable energy?",
"specific_detail_query": "renewable energy investments percentage",
"visual_element_question": "What is the trend of total holding value over time?",
"visual_element_query": "total holding value trend"
}
If there are no relevant visual elements, provide an empty string for the visual element question and query.
Here is the document image to analyze:
Generate the queries based on this image and provide the response in the specified JSON format.
Only return JSON. Don't return any extra explanation text.
We used gemini-1.5-flash-8b to generate the questions and queries.
Note
On the first run, we noticed that we got some extremely long generated questions, so we found adding
maxOutputTokens=500to our generationconfig to be very helpful.
We also noticed some weird questions and queries, for example there were several instances of “string” in the generated questions. We would definitely like to do a more thorough validation of the generated questions and queries.
Python all the way
Our target audience for this demo-app were the ever-growing Data Science and AI community, which most likely played a large factor in Python’s rise to the top as the most popular (and fastest growing) programming language as per GitHub’s State of the Octoverse.
We would nevertheless need to use Python to do the query embedding inference (use colpali-engine-library) in the backend until a ColpaliEmbedder is supported natively in Vespa(WIP, see github issue), and using another language (and framework) for the frontend would add complexity to the project, making it harder for others to replicate the application.
As a consequence, we decided to build the whole application in Python.
Choosing our frontend framework
Streamlit and Gradio
We acknowledge that it is very easy to build simple PoC’s with Gradio and Streamlit, and we have used both in the past for this purpose. There were two main reasons we did not want to go with this.
- We wanted a professional-looking UI that could be used in a production setting.
- We wanted good performance. Waiting for multiple seconds, and the UI intermittently freezing, is not good enough for the showcase we wanted to build.
As much as we enjoy exercise, we are not huge fans of Streamlit’s “running” message in the top right corner of the screen.

FastHTML to the rescue
We are huge fans of answer.ai, so when they released FastHTML3 earlier this year, we were excited to try it out.
FastHTML is a framework to build modern web applications in pure Python. From their vision:
FastHTML is a general-purpose full-stack web programming system, in the same vein as Django, NextJS, and Ruby on Rails. The vision is to make it the easiest way to create quick prototypes, and also the easiest way to create scalable, powerful, rich applications.
FastHTML uses starlette and uvicorn under the hood.
It comes with Pico CSS for styling out of the box. With Leandro, as an experienced web developer on the team wanted to try out Tailwind CSS, and our recent discovery of shad4fast, we decided to go with that to reuse beautiful UI components from the shadcn/ui in FastHTML.
Pyvespa
Our Vespa Python client, pyvespa, has historically been used mainly for prototyping Vespa applications.
However, we have recently made efforts to expose more of Vespa’s features through pyvespa. Deployment to production is now supported, and we recently added support for Advanced Configuration of the Vespa services.xml file through pyvespa. See this notebook for examples and details.
As a consequence, most of the Vespa applications that do not require custom Java components can be built using pyvespa.
Fun fact:
The support for Advanced Configuration in pyvespa was actually inspired by the way FastHTML wraps and converts
ft-components to HTML tags. In pyvespa, we do the same withvt-components, converting them to Vespaservices.xmltags. For those with a particular interest, feel free to check out this PR for details. This saved us a ton of work compared to implementing custom classes for all supported tags.
As an added bonus, we got to dogfood both building a Vespa application and using pyvespa to do it.
Hardware
As a Vespa-native ColPali-embedder, is still WIP, we knew that we would need a GPU to do the inference. From experimenting in Colab, we had the notion that a T4 instance would be sufficient.
To create the embeddings of the pdf pages in the dataset prior to feeding to Vespa, we considered using a serverless GPU-provider (Modal is on our list of favourites). But, since the dataset consists of “only” 6692 pages, we just put a Macbook M2 Pro to work for 5-6 hours to create the embeddings.
Hosting
There were many options here. We could have gone with a traditional cloud provider, such as AWS, GCP or Azure, but this would require a lot more work from our side to set up and manage the infrastructure, and also would make it harder for others to replicate the application.
We knew that Hugging Face Spaces provides a hosting service with the option of adding GPU’s as needed. They also provide a 1-click “clone this space” button, which would make it very easy for others to replicate the application.
We knew that answer.ai had created a reusable library for deploying a FastHTML application on Hugging Face Spaces. But after digging a bit deeper, we discovered that it was even simpler than their approach, which uses the Docker SDK to spaces.
By leveraging the Custom Python Spaces.
From huggingface-hub docs:
While not an official workflow, you are able to run your own Python + interface stack in Spaces by selecting Gradio as your SDK and serving a frontend on port 7860
Fun fact 2:
There was a typo in the docs, stating that the port to be served was 7680. Luckily, we didn’t spend much time figuring out it was supposed to be 7860, and even got a PR merged by Hugging Face CTO, Julien Chaumond, to fix the typo. Bucket list item checked!
Vision Language Model
For the “Generation” part of the Visual RAG, we needed a Vision Language Model (VLM) to generate responses based on the top-k ranked documents from Vespa.
Vespa have native support for LLM’s (Language Language Models), both externally and inside Vespa, but VLM’s (Vision Language Models) is not yet supported natively in Vespa.
OpenAI, Anthropic, and Google have all released great Vision Language Models (VLMs) in the past year, and the field is moving fast. We wanted a smaller model for performance reasons, and with the recently improved Developer experience of Google’s Gemini API, we decided to go with gemini-1.5-flash-8b for this demo.
It would of course be advisable to do a quantitative evaluation of the different models before deciding on one for a production setting, but this was out of scope for this project.
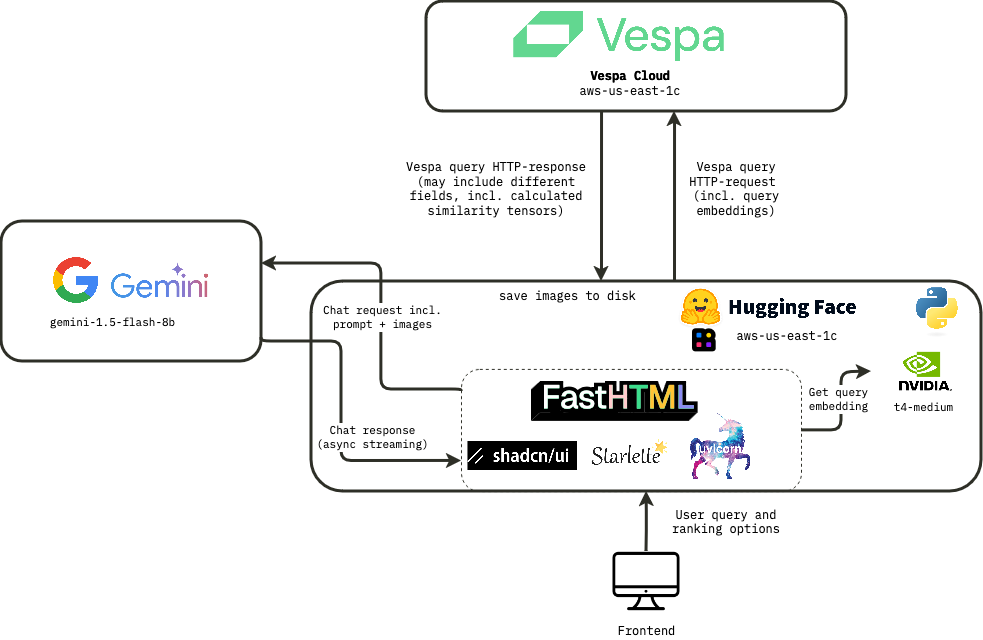
Architecture
With our tech stack in place, we could now start building the application. The high-level architecture of the application is as follows:
Vespa application
The key components of the Vespa application are:
- A document schema definition with fields and types.
- Rank profile definitions.
- A
services.xmlconfiguration file.
All of these can be defined in Python using pyvespa, but we recommend to also inspect the generated configuration files, by calling app.package.to_files(). See pyvespa docs for details.
Rank profiles
One of the most underrated features of Vespa is the phased ranking feature. It allows you to define multiple rank profiles, each with different (or inherited) ranking phases, that can be executed on the content nodes (first and second phase) or the container node(s) (global phase).
This allows us to handle many different use cases separately, and find an attractive trade-off between latency, cost and quality for each of them.
Check out this blog post by our CEO, Jon Bratseth, on architecture inversion, by moving computation to the data.
For this application, we defined 3 different rank profiles:
Note The retrieval phase is specfied in yql at query time, while ranking strategy is specified in the rank profile (part of Application package, supplied at deployment time).
1. Pure Colpali
In our application,the yql used for this ranking mode is:
select title, text from pdf_page where targetHits:{100}nearestNeighbor(embedding,rq{i}) OR targetHits:{100}nearestNeighbor(embedding,rq{i+1}) .. targetHits:{100}nearestNeighbor(embedding,rq{n}) OR userQuery();
We also tuned the hnsw.exploreAdditionalHits parameter to 300, to make sure we don’t miss any relevant hits in the retrieval phase. Note that this has a performance cost.
Where rq{i} is the i-th token in the query (must be supplied as parameter in the HTTP-request), and n is the maximum number of querytokens to be used for retrieval (we use 64 for this application).
This rank profile uses a max_sim_binary-rank expression, which takes advantage of the optimized hamming-distance calculation in Vespa (see Scaling ColPali to billions4 for details.) for first phase ranking, and reranks the top 100 hits using the full float representation of the ColPali embeddings.
2. Pure text based ranking (BM25)
Here, we also retrieve documents based on weakAnd only.
select title, text from pdf_page where userQuery();
In ranking, we use bm25 for first-phase ranking (no second phase).
Note that we would most likely want to combine both text-based and vision-based rank features for optimal performance (using for instance reciprocal rank fusion), but for this demo, we wanted to illustrate the difference between them, rather than finding the optimal combination.
3. Hybrid BM25+ colpali
In the retrieval phase, we use the same yql as for the pure ColPali rank profile.
We noticed that for some queries, especially shorter ones, pure ColPali was matching many pages with no text (images only), while many of the answers we were looking for were in pages with text.
To address this, we added a second phase ranking expression that combines the BM25 score with the ColPali score, using a linear combination of the two scores (max_sim + 2 * (bm25(title) + bm25(text))).
This was based on simple heuristics, and it would be beneficial to find the optimal weights for the different features by performing ranking experiments.
Snippet Generation in Vespa
In search front-ends, it’s common to include some extracts from the source text with some words in bold (highlighting).
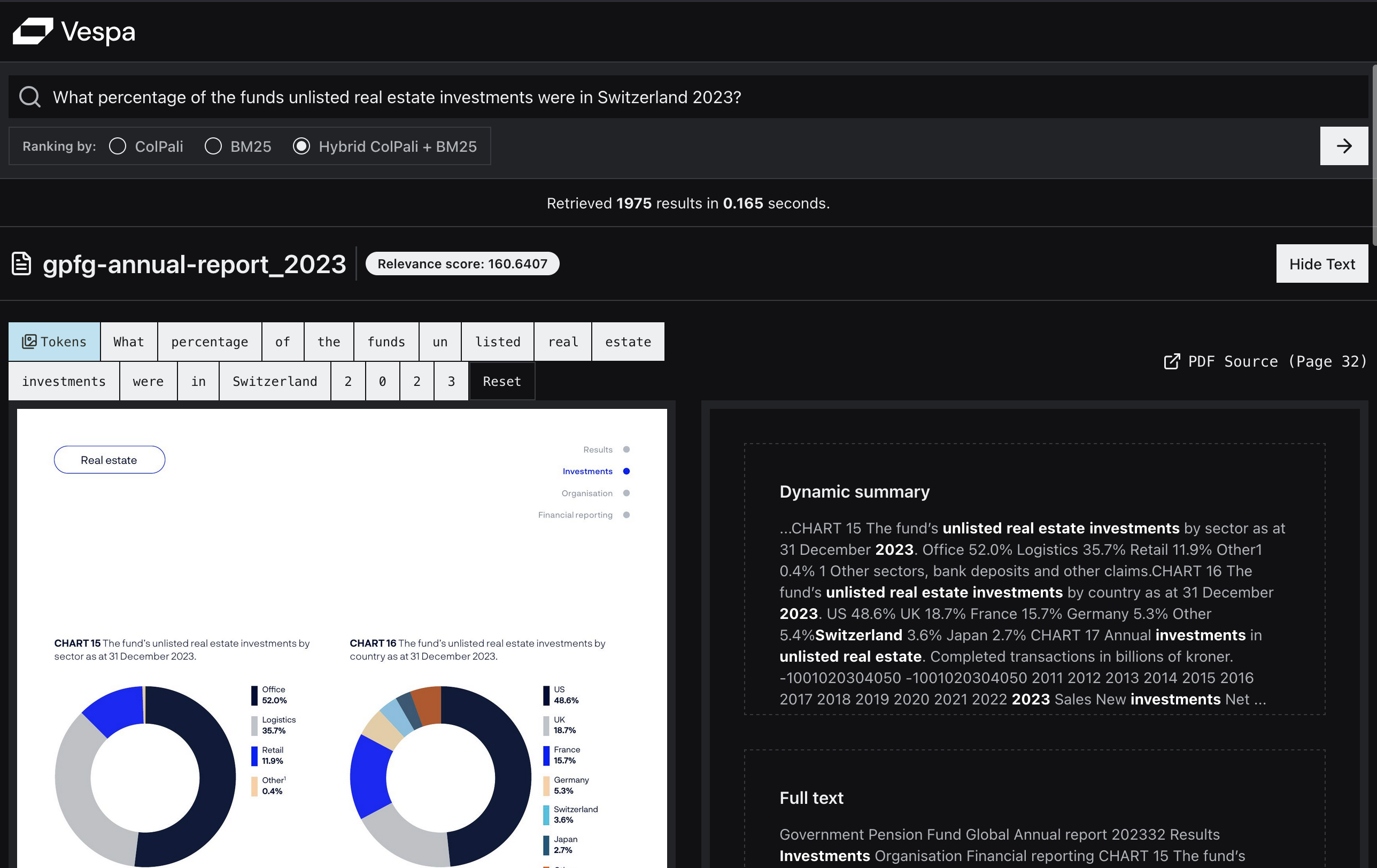
Showing a snippet with the matched query terms in context allows the user to quickly assess if the result is likely to meet their information need.
In Vespa, this functionality is called “dynamic snippets,” and there are several parameters available to tune it, e.g., how much surrounding context to include and which tags to use for highlighting matched terms.
In this demo, we present both the snippet and the full extracted text from the page for comparison.
To reduce visual noise in the results, we remove stopwords (and, in, the, etc.) from the user query so they will not be highlighted.
Learn more about dynamic snippets in Vespa.
Query Suggestions in Vespa
Another common feature in search is “search suggestions,” which appear as you type.
Real user queries are often used to provide pre-computed results, but we don’t have any user traffic to analyze.

Here, instead, we’re using a simple substring search in the typed prefix to suggest matches from the related questions generated from the PDF pages.
The yql query we used for getting the suggestions was:
select questions from pdf_page where questions matches (".*{query}.*")
One advantage of this is that any suggestion which appears is known to have an answer in the available data!
We could have ensured that the page from which the suggested question is generated is always returned in the top-3 responses (by including a similarity between the user query and the document’s generated queries in the rank profile), but that feels a bit like “cheating” from the perspective of trying to give an impression of what the ColPali model can do.
User experience
We were lucky enough to get great feedback on the UX from our Chief Scientist, Jo Bergum, who pushed us to make the UX “snappy”. People are used to Google, and it is no doubt that speed matters when it comes to UX in search (and RAG). This is something we think is still a bit underrated in the AI community, where many seem to be satisfied with waiting 5-10 seconds for a response. We wanted to strive for a response time in milliseconds range.
Based on his feedback, we needed to set up a phased requests flow, to avoid waiting for both the full images and the similarity map tensors to be returned from Vespa before showing the results.
The solution was to first retrieve only the most essential data from the results. For us this means only retrieving title, url, text, page_no, together with a scaled down (blurred) version of the image (32x32 pixels) for the initial search results. This would allow us to show the results immediately, and then continue to load the full images and similarity maps in the background.
The full UX flow is outlined below:
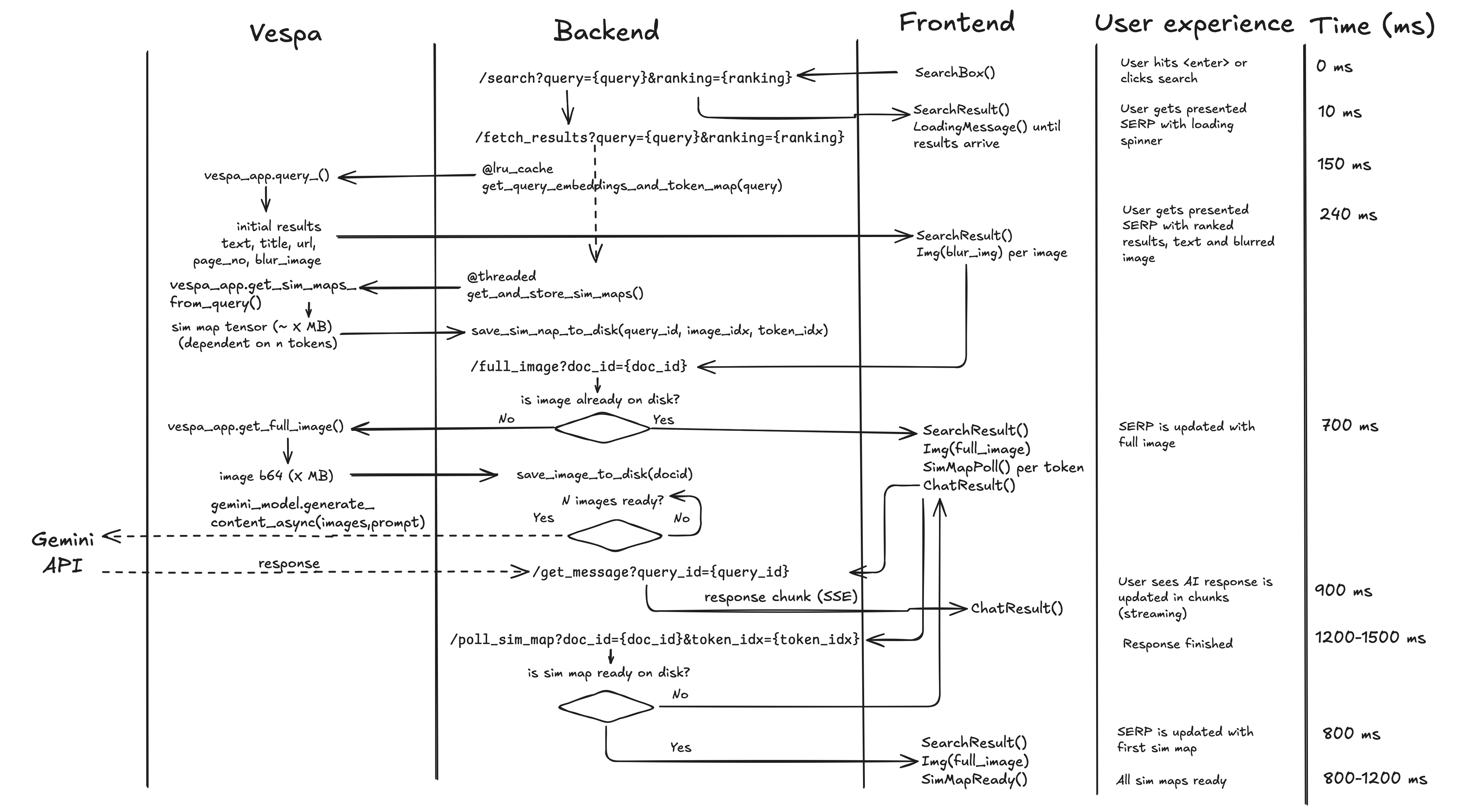
The main contributors to the latency are:
- Inference time for the ColPali embeddings (done on GPU, dependent on the number of tokens in the query)
- This is why we decided to
@lru_cachethis function, to avoid recomputing the embeddings for the same query many times.
- This is why we decided to
- Network latency (incl TCP handshake) between Hugging Face Spaces and Vespa
- The transfer time also become significant for the full images (~0.5MB each)
- The similarity map tensors are even larger (
n_query_tokensxn_imagesx 1030 patches x 128).
- Creating the the similarity map blended image is a CPU-bound task that takes some time, but this is done in a threaded background task, using
fastcore’s@threadeddecorator, and each image polls its corresponding endpoint to check whether the similarity map is ready.
Load testing
We were a bit worried to see how our application would handle a large spike in traffic, so we did a simple load testing experiment.
The experiment was simply to “copy as cURL” a request to the /fetch_results - endpoint from the browser devtools (this was without caching) and running it in a loop in 10 parallel terminals. (We did this with the @lru_cache-decorator disabled).
Results
Although extremely basic, this first test showed that the bottleneck for search throughput was in computing the ColPali embeddings on the GPU in the Huggingface space, and the Vespa back-end was easily able to handle 20+ queries per seconds with low resource usage. We deemed this to be likely to be more than sufficient for the demo, and know that our first course of action if we were to scale this up would be to run a larger GPU instance in the Huggingface space.
As we can see below, the Vespa application had no problem handling the load.
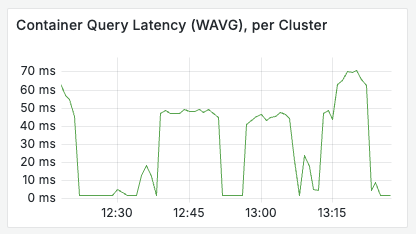

Reflections on using FastHTML
The main takeaway from using FastHTML was that it broke down the barriers between frontend and backend development. The code lives close together, and allowed us all to both understand and contribute to every part of the application. This should not be underestimated.
We really enjoyed being able to use the browser’s devtools to inspect the frontend code, and actually see and understand most of what was going on.
Both the development and deployment process were significantly simplified compared to if we had been using a separate frontend framework.
It allowed us to handle all our dependencies with uv, which has truly revolutionized the way we handle dependencies in Python.
Thomas:
Coming from Data Science and AI, with a preference for Python, but having used several JS frameworks in the past. My experience was extremely positive. I felt empowered to contribute more on frontend-related tasks, without adding a lot of complexity to the project, and I loved being able to understand every part of the application.
Andreas:
I’ve worked on Vespa for a long time, but I haven’t done much of either python or front-end development. Jumping straight in was overwhelming for the first day or two, but it’s very exciting to work on the full stack and being able to see the effect of your changes in near-real-time! And with LLM help, jumping into an unfamiliar environment is easier than ever. I really liked how we were able to compute the image patch similarities with a tensor expression inside Vespa, where the vectors are already stored in memory, and return this along with the search results so the similarity maps could be created with much lower latency and resource usage.
Leandro:
As someone with a solid foundation in web development using React, JavaScript, TypeScript, HTML, and CSS, transitioning to FastHTML has been relatively straightforward. The framework’s direct HTML element mapping aligns well with my previous knowledge, which eased my learning curve. The primary challenge has been adapting to FastHTML’s Python-based syntax, which differs from the standard HTML/JS structure.
Is vision all you need?
We have seen that leveraging token level late interaction embeddings from a Vision Language Model (VLM) can be very powerful for certain types of queries, but we don’t consider it to be a silver bullet, but more like a really valuable tool in the toolbox.
In addition to ColPali, we have also seen other innovations over the last year in the realm of Visual Retrieval. Two particularly interesting approaches are:
- Document Screenshot Embeddings (DSE)5 - A bi-encoder model that generates dense embeddings for screenshots of documents, and uses these embeddings for retrieval.
- Docling6 by IBM - A library to parse a large variety of document types (PDF, PPT, DOCX etc.) to markdown, which sidesteps OCR in favor of Computer Vision models.
Vespa supports combining all of these approaches, and empowers the developers to find the most attractive trade-off between latency, cost and quality for their specific use case.
We could imagine an application with high-quality text extraction from Docling or a similar tool, combined with a dense retrieval using Document Screenshot Embeddings, and ranking combining both text-based features, and MaxSim-scores from a ColPali-like model. If you really wanted to push performance, you could even combine all of these features with a GBDT model like XGBoost or LightGBM.
So, while ColPali may be a powerful tool if you want to make information that is not easily extractable from text searchable, it is not a silver bullet, and you should consider combining it with other approaches for optimal performance.
The missing piece
Models are temporary, but evals are forever.
Adding automated evals are beyond the scope of this demo, but we strongly recommend that you create an evaluation dataset for your particular use case. You can bootstrap it with LLM-as-a-judge (Check out this blog post7 on how we did this for search.vespa.ai).
Vespa has many knobs to tune, and getting quantitative feedback for different experiments will allow you to find attractive trade-offs for your specific use case.
Conclusion
We have built a live demo application showcasing Visual RAG over PDFs using ColPali embeddings in Vespa.
If you have read this far, you are probably interested in the code. You can find the code for the application here.
Now, go you build your own Visual RAG application!
For those interested in learning more about Visual Retrieval, ColPali or Vespa in general, feel free to join the Vespa community on Slack to ask questions, seek assistance from the community, or stay in the loop on the latest Vespa developments.
FAQ
Will using ColPali require a GPU at inference time?
Currently, we need a GPU to do the inference of a query in reasonable time.
In the future, we expect to see both the quality and efficiency (smaller embeddings) of ColPali-like models improve, and we expect to see more models in this direction, exactly like we have seen with ColBERT-like models, with models such as answer.ai’s answerai-colbert-small-v1, now outperforming the original ColBERT model, despite being less than 1/3rd the size.
See the Vespa Blog on how to use
answerai-colbert-small-v1with Vespa.
Can I combine ColPali with query filters in Vespa?
Yes, for this application we added published_year as a field to the pages, but did not get around to implementing it as a filter option in the frontend.
When will Vespa support ColPali embeddings natively?
Can this really scale to billions of documents?
Yes, it can. Vespa scales horizontally, and allows you tailor the trade-off between latency, cost and quality for your specific use case.
Can this demo be adapted to ColQwen2?
Yes, but there are a few differences when it comes to calculating the similarity maps.
See this notebook for a starting point.
Can I use this demo with my own data?
Absolutely! By adapting the provided notebook to point to your own data, you can set up your own Vespa application for Visual RAG. You can also use the provided web application as a starting point for your own frontend.
