Vespa at Zedge - providing personalization content to millions of iOS, Android and web users
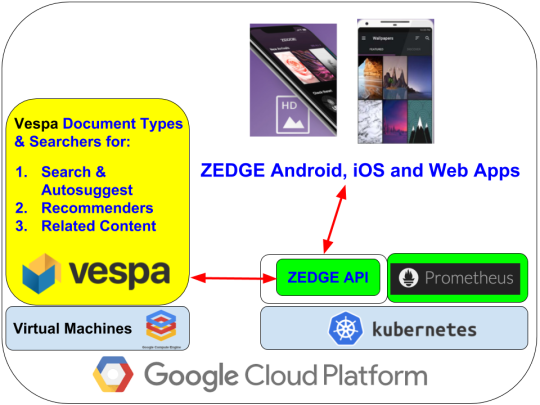
This blog post describes Zedge’s use of Vespa for search and recommender systems to support content discovery for personalization of mobile phones (Android, iOS and Web). Zedge is now using Vespa in production to serve millions of monthly active users. See the architecture below.
What is Zedge?

Zedge’s main product is an app - Zedge Ringtones & Wallpapers - that provides wallpapers, ringtones, game recommendations and notification sounds customized for your mobile device. Zedge apps have been downloaded more than 300 million times combined for iOS and Android and is used by millions of people worldwide each month. Zedge is traded on NYSE under the ticker ZDGE.
People use Zedge apps for self-expression. Setting a wallpaper or ringtone on your mobile device is in many ways similar to selecting clothes, hairstyle or other fashion statements. In fact people try a wallpaper or ringtone in a similar manner as they would try clothes in a dressing room before making a purchase decision, they try different wallpapers or ringtones before deciding on one they want to keep for a while.
The decision for selecting a wallpaper is not taken lightly, since people interact and view their mobile device screen (and background wallpaper) a lot (hundreds of times per day).
Why Zedge considered Vespa
Zedge apps - for iOS, Android and Web - depend heavily on search and recommender services to support content discovery. These services have been developed over several years and constituted of multiple subsystems - both internally developed and open source - and technologies for both search and recommender serving. In addition there were numerous big data processing jobs to build and maintain data for content discovery serving. The time and complexity of improving search and recommender services and corresponding processing jobs started to become high, so simplification was due.

Vespa seemed like a promising open source technology to consider for Zedge, in particular since it was proven in several ways within Oath (Yahoo):
-
Scales to handle very large systems , e.g.
- Flickr with billions of images and
- Yahoo Gemini Ads Platform with more than one hundred thousand request per second to serve ads to 1 billion monthly active users for services such as Techcrunch, Aol, Yahoo!, Tumblr and Huffpost.
- Runs stable and requires very little operations support - Oath has a few hundred - many of them large - Vespa based applications requiring less than a handful operations people to run smoothly.
-
Rich set of features that Zedge could gain from using
- Built-in tensor processing support could simplify calculation and serving of related wallpapers (images) & ringtones/notifications (audio)
- Built-in support of Tensorflow models to simplify development and deployment of machine learning based search and recommender ranking (at that time in development according to Oath).
- Search Chains
- Help from core developers of Vespa
The Vespa pilot project
Given the content discovery technology need and promising characteristics of Vespa we started out with a pilot project with a team of software engineers, SRE and data scientists with the goals of:
- Learn about Vespa from hands-on development
- Create a realistic proof of concept using Vespa in a Zedge app
-
Get initial answers to key questions about Vespa, i.e. enough to decide to go for it fully
- Which of today’s API services can it simplify and replace?
- What are the (cloud) production costs with Vespa at Zedge’s scale? (OPEX)
- How will maintenance and development look like with Vespa? (future CAPEX)
- Which new (innovation) opportunities does Vespa give?
The result of the pilot project was successful - we developed a good proof of concept use of Vespa with one of our Android apps internally and decided to start a project transferring all recommender and search serving to Vespa. Our impression after the pilot was that the main benefit was by making it easier to maintain and develop search/recommender systems, in particular by reducing amount of code and complexity of processing jobs.
Autosuggest for search with Vespa
Since autosuggest (for search) required both low latency and high throughput we decided that it was a good candidate to try for production with Vespa first. Configuration wise it was similar to regular search (from the pilot), but snippet generation (document summary) requiring access to document store was superfluous for autosuggest.
A good approach for autosuggest was to:
-
Make all document fields searchable with autosuggest of type (in-memory) attribute
- https://docs.vespa.ai/en/attributes.html
- https://docs.vespa.ai/en/reference/search-definitions-reference.html#attribute
- https://docs.vespa.ai/en/search-definitions.html (basics)
-
Avoid snippet generation and using the document store by overriding the document-summary setting in search definitions to only access attributes
- https://docs.vespa.ai/en/document-summaries.html
- https://docs.vespa.ai/en/nativerank.html
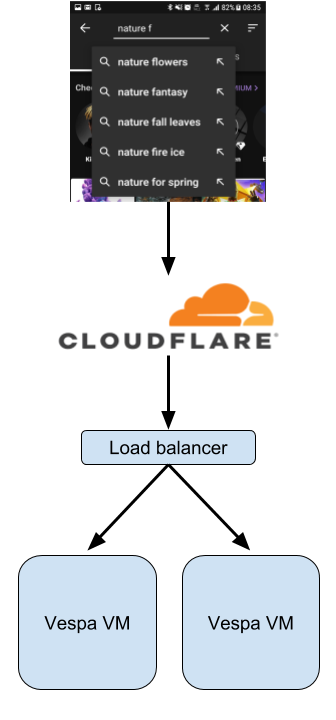
The figure above illustrates the autosuggest architecture. When the user starts typing in the search field, we fire a query with the search prefix to the Cloudflare worker - which in case of a cache hit returns the result (possible queries) to the client. In case of a cache miss the Cloudflare worker forwards the query to our Vespa instance handling autosuggest.
Regarding external API for autosuggest we use Cloudflare Workers (supporting Javascript on V8 and later perhaps multiple languages with Webassembly) to handle API queries from Zedge apps in front of Vespa running in Google Cloud. This setup allow for simple close-to-user caching of autosuggest results.
Search, Recommenders and Related Content with Vespa
Without going into details we had several recommender and search services to adapt to Vespa. These services were adapted by writing custom Vespa searchers and in some cases search chains:
- https://docs.vespa.ai/en/applications/searchers.html
- https://docs.vespa.ai/en/chained-components.html
The main change compared to our old recommender and related content services was the degree of dynamicity and freshness of serving, i.e. with Vespa more ranking signals are calculated on the fly using Vespa’s tensor support instead of being precalculated and fed into services periodically. Another benefit of this was that the amount of computational (big data) resources and code for recommender & related content processing was heavily reduced.
Continuous Integration and Testing with Vespa
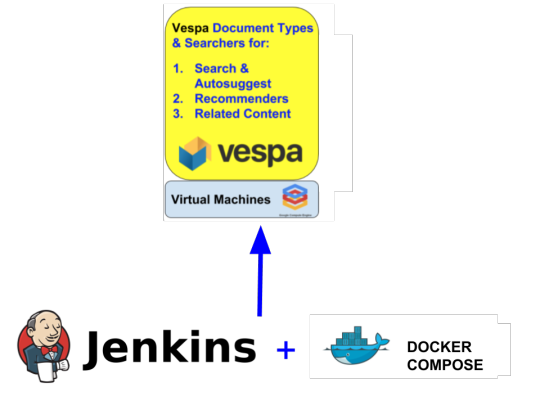
A main focus was to make testing and deployment of Vespa services with continuous integration (see figure below). We found that a combination of Jenkins (or similar CI product or service) with Docker Compose worked nicely in order to test new Vespa applications, corresponding configurations and data (samples) before deploying to the staging cluster with Vespa on Google Cloud. This way we can have a realistic test setup - with Docker Compose - that is close to being exactly similar to the production environment (even at hostname level).
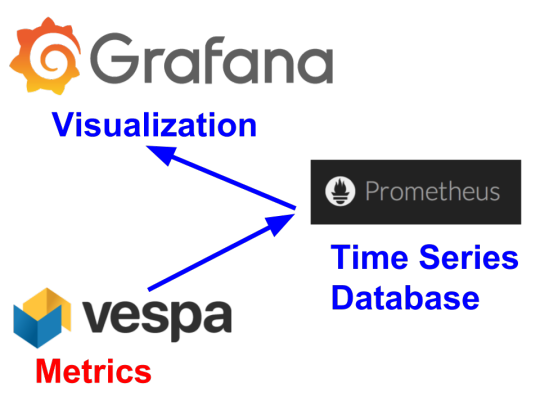
Monitoring of Vespa with Prometheus and Grafana
For monitoring we created a tool that continuously read Vespa metrics, stored them in Prometheus (a time series database) and visualized them them with Grafana. This tool can be found on https://github.com/vespa-engine/vespa_exporter. More information about Vespa metrics and monitoring:
- https://docs.vespa.ai/en/reference/metrics-health-format.html
- https://docs.vespa.ai/en/reference/metrics.html
- https://docs.vespa.ai/en/monitoring.html
Conclusion
The team quickly got up to speed with Vespa with its good documentation and examples, and it has been running like a clock since we started using it for real loads in production. But this was only our first step with Vespa - i.e. consolidating existing search and recommender technologies into a more homogeneous and easier to maintain form.
With Vespa as part of our architecture we see many possible paths for evolving our search and recommendation capabilities (e.g. machine learning based ranking such as integration with Tensorflow and ONNX).
Best regards,
Zedge Content Discovery Team