

How Onyx.app saved 25% with a safe and straightforward automated configuration change, with zero work to optimize spending and performance
Meet Onyx: Open-Source AI for Enterprise Knowledge
Onyx (formerly known as Danswer) is an open-source AI platform that helps teams instantly find and use institutional knowledge scattered across internal tools, documents, and conversations. Inspired by the founders’ experiences at startups and large enterprises, Onyx was built to eliminate the friction of digging through knowledge bases, shared drives, and outdated documentation.
With Onyx, companies can deploy:
- AI-Powered Workplace Search across 40+ applications
- Custom AI Assistants grounded in your org’s unique internal knowledge and available right where you work
- Developer APIs for building tailored GenAI workflows
Designed for fast-moving teams and secure enterprises alike, Onyx offers flexible deployment options and scales from small teams to global organizations like Netflix and Thales Group.
The Challenge: Scaling without Slowing Down
As Onyx’s user base grew, so did the complexity of managing their self-hosted Vespa deployment. Vespa’s architecture offers powerful flexibility: teams can scale horizontally, resize clusters, and tune performance parameters. But identifying the ideal balance between cost and performance takes time, experimentation, and monitoring. For a lean, fast-moving team like Onyx, the priority was clear: focus on building, not infrastructure management.
In the early stages, the infrastructure strategy was straightforward: avoid running out of disk or memory, and provision enough CPU to keep query performance strong. But as Onyx onboarded more customers and ingested more data with heavier workloads, system demands grew significantly.
By this point, schemas had stabilized, and usage patterns were clearer. There was finally enough operational data and traffic to assess optimization opportunities and identify the right balance of performance and cost: what is the sweet spot, given the current load? In theory, most platforms allow teams to detect overprovisioned resources and right-size clusters.
The real challenge, however, wasn’t identifying what to change. It was finding the time to make the changes. Reconfiguring infrastructure takes time and operational effort, both of which were in short supply for a team focused on delivering new features and meeting customer demand.
Their early move to Vespa Cloud proved valuable. It allowed them to offload operational complexity while preserving the scalability and responsiveness of their system.
Smarter Optimization with Vespa Cloud
With Vespa Cloud, the Onyx team gained access to resource insights and suggestions that made it easy to scale efficiently, without sacrificing performance or engineering time.
Optimize More, Manage Less
Vespa Cloud gives teams actionable guidance to fine-tune performance and reduce costs through:
- Performance Monitoring & Insights: Continuously tracks system usage and highlights opportunities to optimize for throughput, latency, and stability.
- Resource Suggestions: Analyzes historical workload patterns and recommends optimal resource configurations.
- Automated Instance Migration: Supports seamless transitions to more affordable instance types, guided by real-world usage and performance needs, with zero downtime.
Built for Developer Efficiency and Stability
Getting the most out of Vespa in production is all about smart configuration, using Vespa Cloud automated deployments:
- Hassle-Free Operations: OS upgrades, Vespa version updates, node replacement, and load balancing are handled automatically, following best practices for availability, security, and scale.
- Safe CI/CD Pipelines: Application updates, schema changes, and infrastructure migrations are orchestrated safely across zones with built-in validation, rollback mechanisms, and redundancy.
- Built-In Expert Support: On-demand and annual performance tune-ups with Vespa engineers help identify optimization opportunities, often resulting in up to 50% cost reductions.
From Insight to Action: Cost Savings in Minutes
The Vespa Cloud Scaling View revealed clear patterns in Onyx’s resource usage and growth trajectory:
- The cost has increased with time, with the growth of the application
- The application is memory-bound, with memory peaking at 61% utilization—a healthy level indicating good sizing.
- It is more memory-bound than disk-bound, which is ideal for cost savings.
- CPU usage remained low, signaling that Onyx was overprovisioned on vCPUs—a costly inefficiency, since CPU is typically the most expensive resource in cloud environments.
This imbalance, which is common among fast-growing applications, highlighted an opportunity to reduce waste without performance risk.
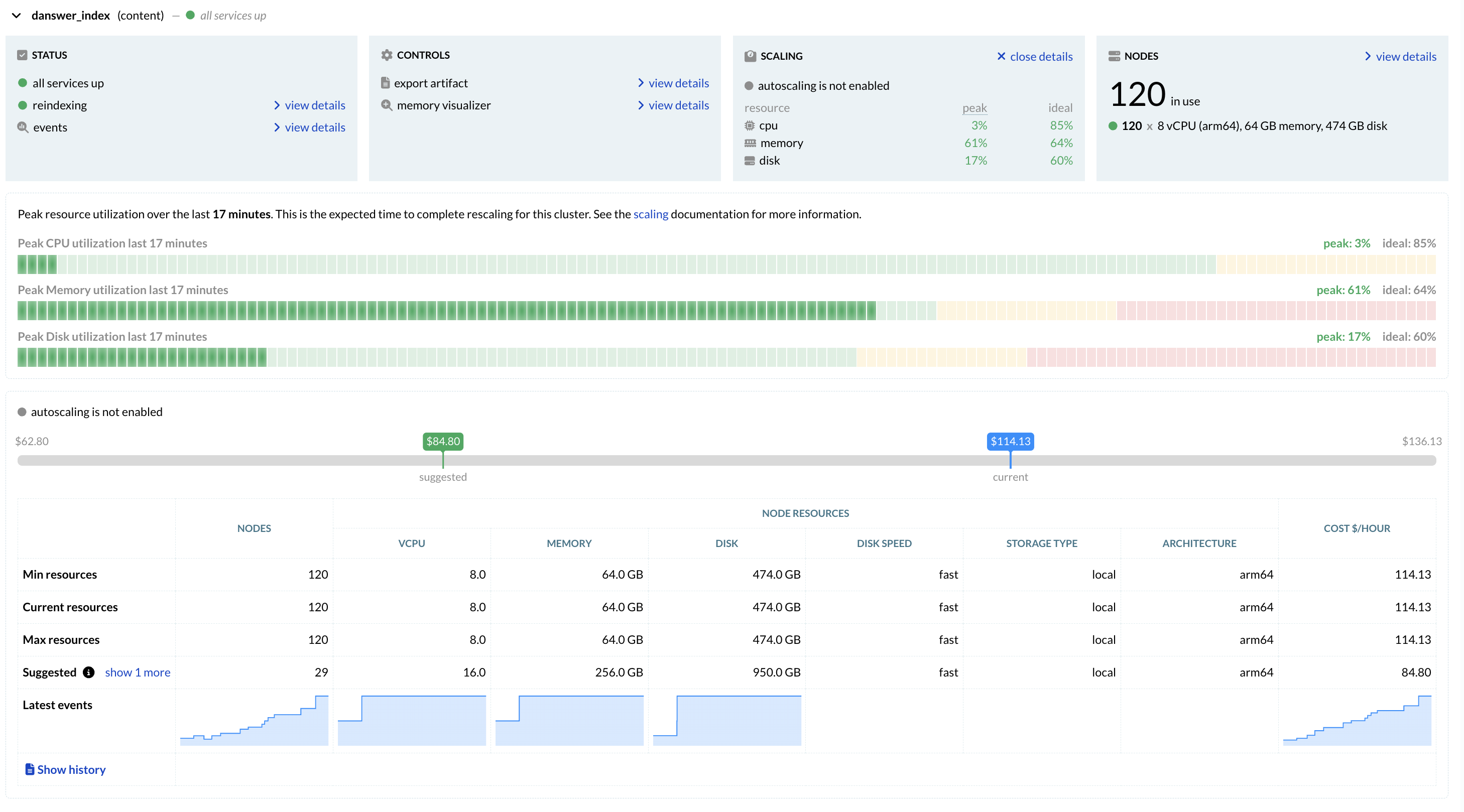
Vespa Cloud’s Suggestion feature monitors historical resource usage and recommends configuration changes to reduce waste.
Instead of overprovisioning, the team followed Vespa’s recommendation to rebalance their cluster. Based on the previous week’s peak load, Vespa Cloud suggested:
- Keeping total memory close to constant
- Cutting total CPU from 960 vCPUs (120 nodes × 8 vCPU) to 464 vCPUs (29 nodes × 16 vCPU), using larger nodes
- Halving total disk to 27.5 Tb
This simple change brought the hourly cost down from $114.13 to $84.80.
Seamless Migration via Vespa Cloud’s Built-in CD Pipeline
In self-managed environments, optimization efforts like resizing clusters or changing instance types often get postponed because they require careful monitoring, manual tuning, and risk downtime if done incorrectly. With Vespa Cloud, this entire process is automated, safe, and straightforward.
A Three-Step Optimization Workflow
What would normally be a risky and complex change in a self-managed environment became a three-step process:
1. Update the configuration
Make the three-line change in services.xml to redefine the node layout:
- <nodes count="120">
- <resources vcpu="8.0" memory="64.0Gb" architecture="arm64" storage-type="local"
- disk="474.0Gb" />
+ <nodes count="60">
+ <resources vcpu="8.0" memory="128.0Gb" architecture="arm64" storage-type="local"
+ disk="475.0Gb" />
2. Deploy via Vespa Cloud’s built-in CI/CD Pipeline
Vespa Cloud provides a built-in continuous deployment system using
automated deployments
that safely rolls out infrastructure changes, tracks version history, and coordinates transitions across zones.
An example of how resource allocations are tracked:
2025-08-01 12:56Z: 120 ➔ 60 nodes with 8.0 vcpu, 64.0 GB ➔ 128.0 GB memory, 474.0 GB ➔ 475.0 GB (fast, local) disk, arm64
2025-07-14 01:29Z: 90 ➔ 120 nodes with 8.0 vcpu, 64.0 GB memory, 474.0 GB (fast, local) disk, arm64
3. Observe the automated data migration
A change like this is an instance type migration.
Vespa Cloud will allocate the new nodes (here 60), add them to the application, migrate data, and finally release the old nodes.
Latency remains stable during migration, thanks to Vespa’s prioritization of user-facing traffic.
Automating this procedure makes it both quick, safe and easy to optimize clusters, as illustrated by a snapshot from the data migration process:
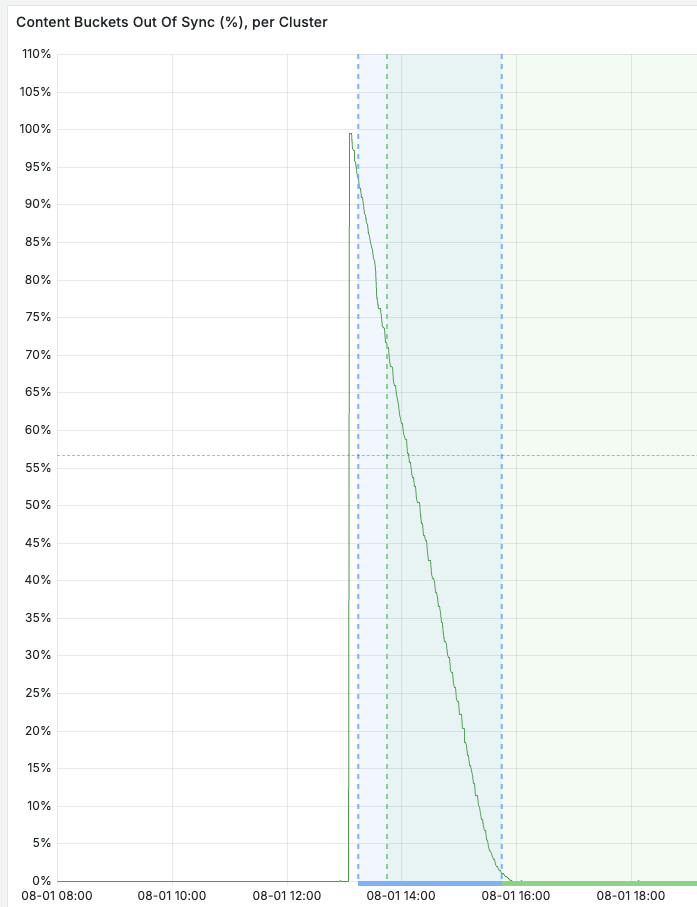
The effect? A 24.5% cost reduction. Not bad for a few minutes’ work!
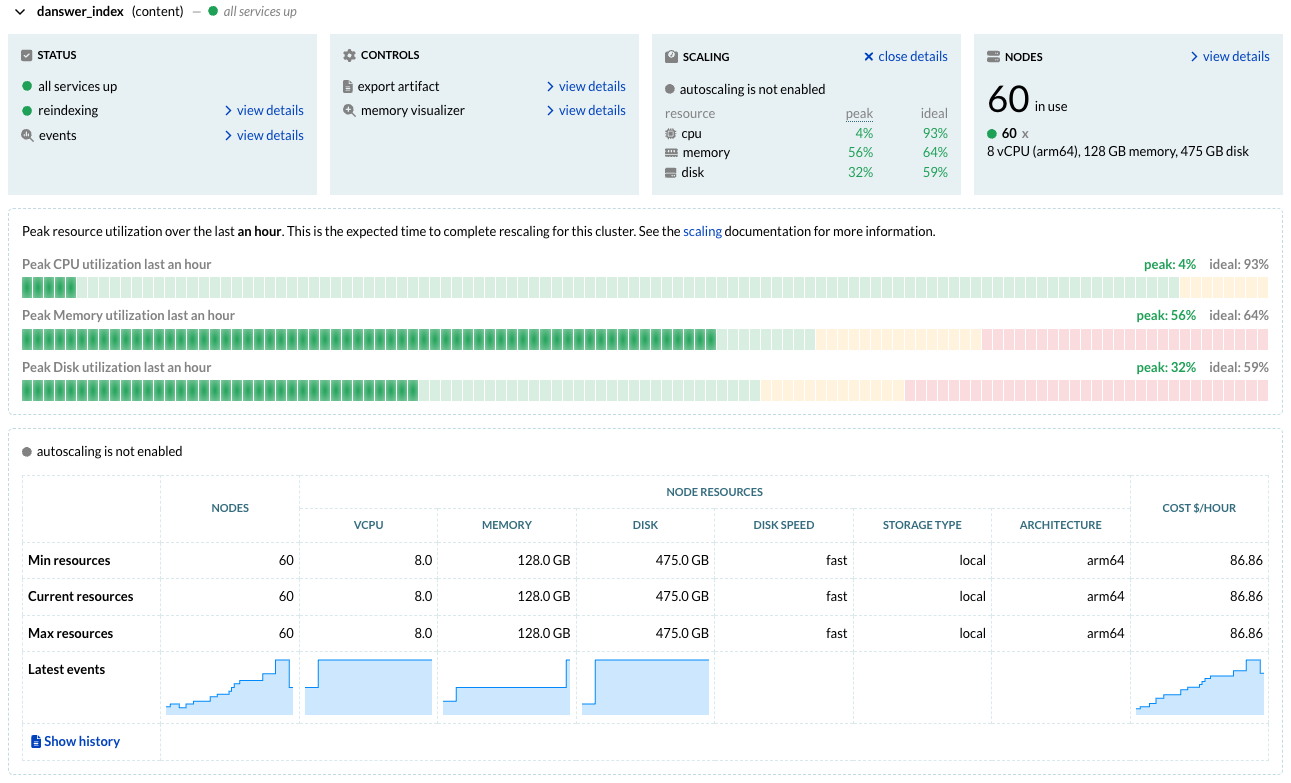
Smooth, Zero-Downtime Migration
One of the key advantages of Vespa Cloud’s automation is that infrastructure changes can be made safely, without interrupting service:
- The cluster remains fully operational during data migration—no special preparation or maintenance window is required.
- The data migration feature is tuned to minimize impact on latencies, prioritizing query load, ensuring that user-facing performance remains stable even as data is moved across nodes.
- While CPU usage temporarily increases, Vespa’s prioritization model ensures little observable impact on average, p95, or p99 query latencies - in this case, zero impact.
The example below shows the live transition from 120 nodes ➝ 180 nodes ➝ 60 nodes, as the new configuration is phased in and the old one phased out.
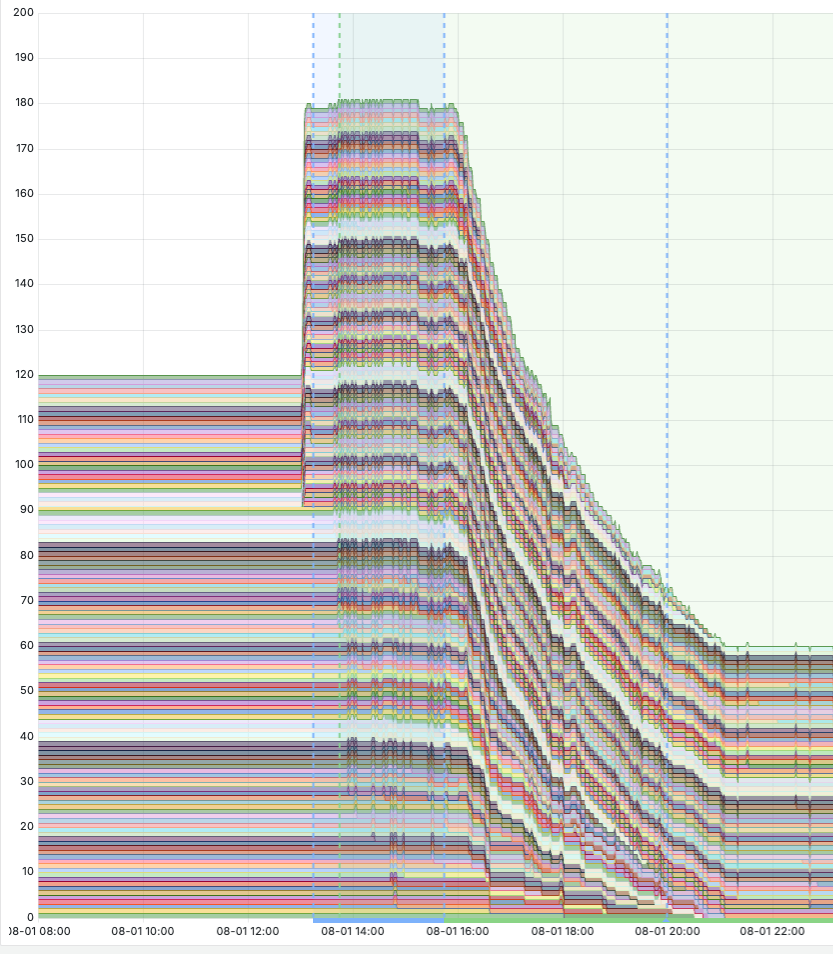
The daily infrastructure cost shows only a minor temporary increase on the day of migration:
- Daily cost before migration: $2,751.92
- Day of migration: $2,883.63

This illustrates how Vespa Cloud enables safe, incremental infrastructure optimization with negligible disruption and minimal cost overhead. Which in Onyx’s case resulted in an overall 24.5% cost reduction.
Poised for Growth: What’s Next for Onyx
With baseline optimizations in place, Onyx is now in a position to explore more advanced trade-offs to further optimize efficiency at scale as their application and user base continue to grow.
The next phase involves further optimizations, evaluating deeper architectural and relevance-impacting decisions, such as:
-
Streaming Search: Should the fields use disk-based streaming search instead of being held in memory with indexes? For many Enterprise GenAI and Personal Search use cases, streaming is a highly viable approach, which often cuts memory cost to 15%.
-
Topology + thread tuning: Is the current cluster layout optimal, or should Onyx adopt query performance groups for better isolation and responsiveness? How low can the vCPU allocation per node go without impacting latency? Fine-tuning these parameters can yield significant performance-per-dollar gains.
-
Binarized embeddings + multi-phase ranking: Can Onyx reduce memory usage by switching to binarized in-memory vectors with full-precision on disk? And what effect might that have on search relevance? With Vespa’s support for multi-phase ranking, these strategies can be tested safely before rollout.
As Onyx continues to scale, they’ll benefit from Vespa Cloud’s ability to support these kinds of iterative experiments alongside tooling, automation, and guidance from the Vespa team to make safe, data-driven decisions.
Conclusion: Continuous Optimization Made Simple
Onyx’s journey shows how even a simple, automated configuration change, powered by real-time insights, can yield big results. Vespa Cloud’s unique combination of automation, performance tooling, and expert support empowers teams to:
- Optimize frequently, without disruption
- Resize infrastructure as schemas evolve
- Take advantage of committed spend options to drive even greater savings
And because it’s safe and fast to deploy, the best teams do this continuously. Follow Onyx’s lead: start with the easy wins, then keep optimizing.
As usage grows, many teams also take advantage of Committed Spend options, which immediately reduce costs without affecting service performance. Commitments can be adjusted over time as needs evolve.
And if you’re ever unsure? The Vespa team is available to help. With years of experience supporting enterprise-scale applications, we offer practical guidance to help you identify savings, improve performance, and tune with confidence.
We will post more blogs on application optimizations, including autoscaling. For now, you can follow Onyx’s example and do the easy things first.
Further reads
- Vespa performance is best in class, see the Report.
- Vespa Cloud Pricing Plans let users get access to the Vespa Team Performance experts, who can help with more advanced tuning, based on app specifics.
- Vespa Cloud has a powerful toolbox to let you understand your application’s performance. Optimizing your application is a combination of using the built-in tools like the Resource Analyzer (above) and the Memory Visualizer - also see Vespa performance.
- As the cost of changing the system is virtually zero (and safe), little advance planning is needed - just get started, and observe results - read more in Vespa Elasticity.

