An open source sample application that contains everything you need to create a RAG solution with world-class accuracy and infinite scalability
Vespa provides the RAG solution for industry leaders like Perplexity. It contains everything you need for quality and scalability, but putting it all together has been a challenge. With the RAG Blueprint, we’re putting this within everyone’s reach.
Retrieval Augmented Generation (RAG) is in theory a simple concept. Find information that is relevant to a user’s query, give it to an LLM, and generate an answer based on the given information. But how do you find the most relevant information? And more so; how do you find the most relevant information when you have millions, if not billions of documents, and need to serve thousands, if not millions of users, all within a tenth of a second?
The RAG Blueprint is your answer! The blueprint is built on Vespa and is a collection of best practices and guidelines for designing, evaluating and deploying scalable RAG applications. It walks you through the steps you need to do and the considerations you need to make for each step, in order to create a RAG application that delivers high quality results at scale.
When developing a RAG application, you will encounter many challenges and decisions you need to make.
Below are some that we address in the RAG Blueprint:
How to define your searchable unit? Your searchable unit is the unit of information that you will pass to the LLM. It is the searchable units you will be searching through to find the best information to provide your LLM. The RAG Blueprint guides you on how to optimise your searchable unit to make them easier and quicker to find, thus increasing the accuracy, speed and quality of retrieval.
How to select your retrieval strategy? Should you use semantic, text, or both to find the best documents/searchable units? What kind of embedding model should you use? How you choose to retrieve your documents can drastically affect performance and careful consideration must be given to your need for speed and accuracy.
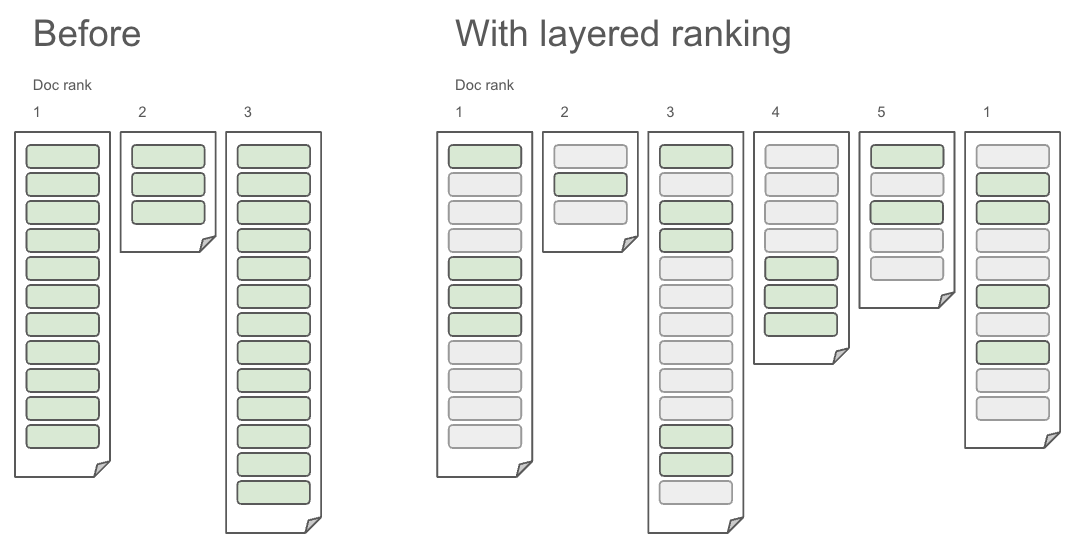
How to rank and rerank the retrieved documents? Vespa supports multiphased ranking of the retrieved documents, but knowing what formula to use for combining the different document scoring metrics is near impossible to figure out manually. To reach the quality and scalability of a production ready RAG application we need to use machine learning.
How to use machine learning to optimise document ranking? With machine learning we can learn how to weigh each document metric to produce a scoring function that most accurately ranks the documents. The RAG Blueprint shows both how to use machine learning for the weights of a cheap first-phase linear ranking function, and to create a more complex GBDT model for second-phase ranking. Using these methods new data can be collected continuously and automatically in order to improve the models.
How to quantify and evaluate each step of your retrieval and ranking pipeline? We show how to break down each step of your retrieval and ranking pipeline, and quantify the quality and performance individually. This allows you to approach each step with a scientific mindset, and make data-driven decisions instead of guessing.
How to facilitate many different use cases with the same search application? We see that agentic retrieval (search being performed by LLMs) has different characteristics than search for human consumers. LLMs can handle more context, and are not as latency-sensitive as human consumers. How do you serve these different users and use cases from one application?
How to make sure the LLM is only given relevant context? As your document corpus scales, the likelihood that some of your documents are unreasonably large increases. How do you make sure only the relevant parts of these large documents are actually returned to the LLM. We show how you can do automatic chunking and rank chunks (as well as documents) and return only the top-ranked chunks.
Are you ready to dive into the details of the RAG Blueprint?
Look no further: