

Photo by Annie Spratt on Unsplash
Vespa is built to scale; documents are distributed across any number of content nodes, and queries and document
operations pass concurrently through the container layer in front. The container
/document/v1/ API is intended for reading
and writing documents, but while it supports high-throughput feeding,
it has only provided limited throughput for bulk reads, i.e., visiting, that is, until now!
This blog post shows how a new slicing feature lets
visiting throughput scale with the number of
containers or clients used for visiting, whichever is the bottleneck.
Visiting Vespa
Visiting is an iteration through all documents stored on the Vespa content
nodes, with an optional document selection for filtering.
Matched documents are sent to a specified destination—typically the client initiating the visit. This lets users dump
their entire corpus, or retrieve all documents matching some criterion, using a minimum of resources. It is also used to
power the update-where and
delete-where endpoints in /document/v1.
When using the visit endpoint, the receiver of the visited documents is first the serving container, and then the HTTP client. To keep the visit endpoint stateless, the state of the visitor must be local to the HTTP request. This means that each visitor can only fill a single HTTP response, and end-to-end throughput from a single visitor is limited by the HTTP throughput of a single container node, which is typically much lower than the throughout from the content nodes to this container. Release 7.499.15 of Vespa addresses both of these issues: increasing HTTP throughput of a single container, and allowing a visit to be served by several containers.
Improving throughput
The simplest improvement is to stream the HTTP responses, lowering the time to first byte, and allowing more data per HTTP exchange, thus reducing HTTP overhead. Enabling this is particularly effective when network latency is high relative to the bandwidth consumed.
The most impactful improvement, which provides scalability, is to partition the documents into independent subsets, allowing multiple visitors to iterate through the full corpus independently of each other. This lets a single, logical visit be performed by multiple, concurrent HTTP exchanges, which can be distributed across any number of containers, and also clients! The Vespa documentation has a sample script for dumping all documents, which visits across multiple slices in parallel. For maximum throughput, take care to scale the number of slices with the number of container nodes.
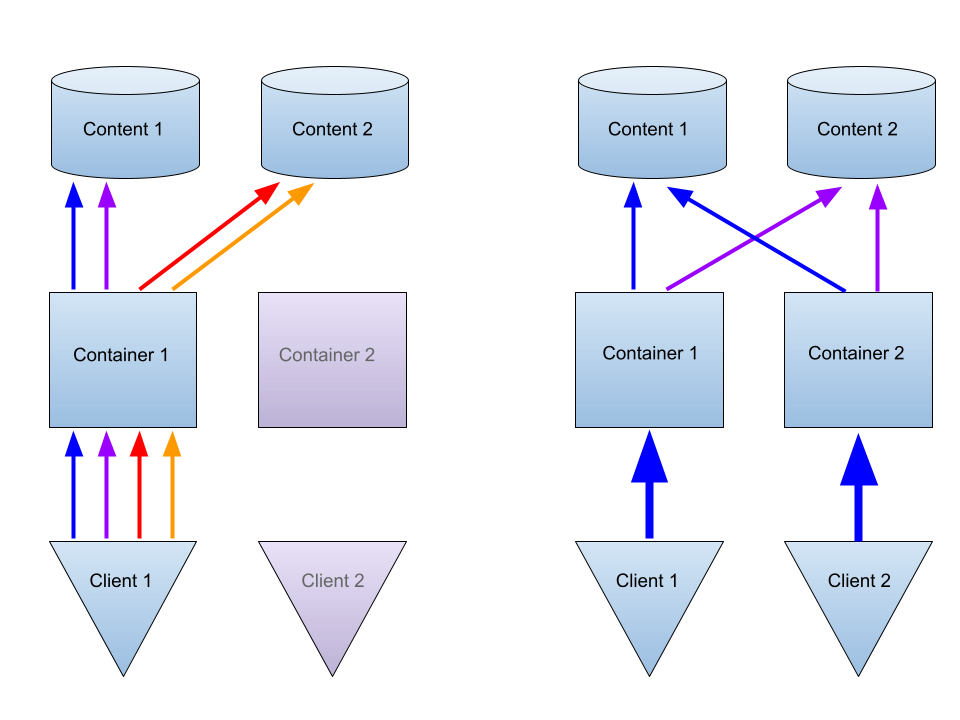
The below drawing illustrates a single client making 4 successive HTTP calls to fetch parts 1, 2, 3 and 4 of the corpus,
on the left; and two parallel clients, each making a single call to fetch parts 1 and 3, and 2 and 4.
Benchmarks
The effectiveness of these improvements was evaluated against some applications we operate in the Vespa cloud. One of the applications had only 2 container nodes, with limited resources, and high GC pressure and memory utilisation. With the client in the same geographical region, throughput without slicing was measured at 0.33Gbps, and increased to 1.12Gpbs when slicing was used. This caused only a minor increase in GC activity, but mostly saturated the 2 vCPU on each of the containers.
Another application that was used had 5 container nodes, with plenty of resources to spare. With the client in the same data centre as the application, throughput without slicing was measured at 0.26Gbps, while throughput increased to 3.3Gpbs with slicing. When the client was on the opposite coast of North America, the numbers were 0.14Gpbs vs 3.2Gpbs. In both cases, the visit increased CPU utilisation by around 6 vCPU.
The reason for the worse performance for the coast-to-coast setup, prior to slicing, is that only parts of the corpus are contained in each HTTP request, and the next HTTP request cannot be sent before the previous response has been processed, and the continuation token extracted. Simply turning on streamed responses increased throughput to 0.22Gbps (+50%) for the coast-to-coast setup.
Summary
In summary, these new features increase visiting throughput for a single Vespa HTTP container by at least a factor 2. Moreover, it allows visiting throughput to scale with the number of containers or clients, whichever is the bottleneck. The features are available since release 7.499.15, so make sure to update your installation, if visiting is for you!