Serving article comments using reinforcement learning of a neural net
Don’t look at the comments. When you allow users to make comments on your content pages you face the problem that not all of them are worth showing — a difficult problem to solve, hence the saying. In this article I’ll show how this problem has been attacked using reinforcement learning at serving time on Yahoo content sites, using the Vespa open source platform to create a scalable production solution.
Yahoo properties such as Yahoo Finance, News and Sports allow users to comment on the articles, similar to many other apps and websites. To support this the team needed a system that can add, find, count and serve comments at scale in real time. Not all comments are equally as interesting or relevant though, and some articles can have hundreds of thousands of comments, so a good commenting system must also choose the right comments among these to show to users viewing the article. To accomplish this, the system must observe what users are doing and learn how to pick comments that are interesting.
Here I’ll explain how this problem was solved for Yahoo properties by using Vespa — the open source big data serving engine. I’ll start with the basics and then show how comment selection using a neural net and reinforcement learning was implemented.
Real-time comment serving
As mentioned, the team needed a system that can add, find, count, and serve comments at scale in real time. The team chose Vespa, the open big data serving engine for this, as it supports both such basic serving as well as incorporating machine learning at serving time (which we’ll get to below). By storing each comment as a separate document in Vespa, containing the ID of the article commented upon, the ID of the user commenting, various comment metadata, and the comment text itself, the team could issue queries to quickly retrieve the comments on a given article for display, or to show a comment count next to the article:

In addition, this document structure allowed less-used operations such as showing all the articles of a given user and similar.
The Vespa instance used at Yahoo for this store about a billion comments at any time, serve about 12.000 queries per second, and about twice as many writes (new comments + comment metadata updates). Average latency for queries is about 4 ms, and write latency roughly 1 ms. Nodes are organized in two tiers as a single Vespa application: A single stateless cluster handling incoming queries and writes, and a content cluster storing the comments, maintaining indexes and executing the distributed part of queries in parallel. In total, 32 stateless and 96 stateful nodes are spread over 5 regional data centers. Data is automatically sharded by Vespa in each datacenter, in 6–12 shards depending on the traffic patterns of that region.
Ranking comments
Some articles on Yahoo pages have a very large number of comments — up to hundreds of thousands are not uncommon, and no user is going to read all of them. Therefore it is necessary to pick the best comments to show each time someone views an article. Vespa does this by finding all the comments for the article, computing a score for each, and picking the comments with the best scores to show to the user. This process is called ranking. By configuring the function to compute for each comment as a ranking expression in Vespa, the engine will compute it locally on each data partition in parallel during query execution. This allows executing these queries with low latency and ensures that more comments can be handled by adding more content nodes, without causing an increase in latency.
The input to the ranking function is features which are typically stored in the document (here: a comment) or sent with the query. Comments have various features indicating how users interacted with the comment, as well as features computed from the comment content itself. In addition, the system keeps track of the reputation of each comment author as a feature.
User actions are sent as update operations to Vespa as they are performed. The information about authors is also continuously changing, but since each author can write many comments it would be wasteful to have to update each comment every time there is new information about the author. Instead, the author information is stored in a separate document type — one document per author, and a document reference in Vespa is used to import that author feature into each comment. This allows updating the author information once and have it automatically take effect for all comments by that author.
With these features, it’s possible in Vespa to configure a mathematical function as a ranking expression which computes the rank score or each comment to produce a ranked list of the top comments, like the following:
Using a neural net and reinforcement learning
The team used to rank comments with a handwritten ranking expression having hardcoded weighting of the features. This is a good way to get started but obviously not optimal. To improve it they needed to decide on a measurable target and use machine learning to optimize towards it.
The ultimate goal is for users to find the comments interesting. This can not be measured directly, but luckily we can define a good proxy for interest based on signals such as dwell time (the amount of time the users spend on the comments of an article) and user actions (whether users reply to comments, provide upvotes and downvotes, etc). The team knew they wanted user interest to go up on average, but there is no way to know what the correct value of the measure of interest might be for any single given list of comments. Therefore it’s hard to create a training set of interest signals for articles (supervised learning), so reinforcement learning was chosen instead: Let the system make small changes to the live machine-learned model iteratively, observe the effect on the signal used as a proxy for user interest, and use this to converge on a model that increases it.
The model chosen here was a neural net with multiple hidden layers, roughly illustrated as follows:
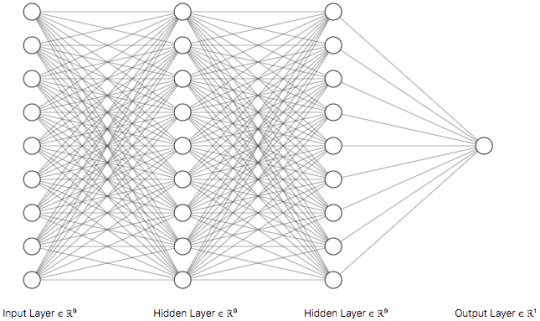
The advantage of using a neural net compared to a simple function such as linear regression is that it can capture non-linear relationships in the feature data without anyone having to guess which relationship exists and hand-write functions to capture them (feature engineering).
To explore the space of possible rankings, the team implemented a sampling algorithm in a Searcher to perturb the ranking of comments returned from each query. They logged the ranking information and user interest signals such as dwell time to their Hadoop grid where they are joined. This generates a training set each hour which is used to retrain the model using TensorFlow-on-Spark, which produces a new model for the next iteration of the reinforcement learning cycle.
To implement this on Vespa, the team configured the neural net as the ranking function for comments. This was done as a manually written ranking function over tensors in a rank profile. Here is the production configuration used:
rank-profile neuralNet {
function get_model_weights(field) {
expression: if(query(field) == 0, constant(field), query(field))
}
function layer_0() { # returns tensor(hidden[9])
expression: elu(xw_plus_b(nn_input, get_model_weights(W_0), get_model_weights(b_0), x))
}
function layer_1() { # returns tensor(out[9])
expression: elu(xw_plus_b(layer_0 get_model_weights(W_1), get_model_weights(b_1), hidden))
}
# xw_plus_b returns tensor(out[1]), so sum converts to double
function layer_out() {
expression: sum(xw_plus_b(layer_1, get_model_weights(W_out), get_model_weights(b_out), out))
}
first-phase {
expression: freshnessRank
}
second-phase {
expression: layer_out
rerank-count: 2000
}
}
More recently Vespa added support for deploying TensorFlow SavedModels directly (as well as similar support for tools saving in the ONNX format), which would also be a good option here since the training happens in TensorFlow.
Neural nets have a pair of weight and bias tensors for each layer, which is what the team wanted the training process to optimize. The simplest way to include the weights and biases in the model is to add them as constant tensors to the application package. However, with reinforcement learning it is necessary to be able to update these tensor parameters frequently. This could be achieved by redeploying the application package frequently, as Vespa allows that to be done without restarts or disruption to ongoing queries. However, it is still a somewhat heavy-weight process, so another approach was chosen: Store the neural net parameters as tensors in a separate document type in Vespa, and create a Searcher component which looks up this document on each incoming query, and adds the parameter tensors to it before it’s passed to the content nodes for evaluation.
Here is the full production code needed to accomplish this serving-time operation:
import com.yahoo.document.Document;
import com.yahoo.document.DocumentId;
import com.yahoo.document.Field;
import com.yahoo.document.datatypes.FieldValue;
import com.yahoo.document.datatypes.TensorFieldValue;
import com.yahoo.documentapi.DocumentAccess;
import com.yahoo.documentapi.SyncParameters;
import com.yahoo.documentapi.SyncSession;
import com.yahoo.search.Query;
import com.yahoo.search.Result;
import com.yahoo.search.Searcher;
import com.yahoo.search.searchchain.Execution;
import com.yahoo.tensor.Tensor;
import java.util.Map;
public class LoadRankingmodelSearcher extends Searcher {
private static final String VESPA_ID_FORMAT = "id:canvass_search:rankingmodel::%s";
// https://docs.vespa.ai/en/ranking-expressions-features.html#using-query-variables
private static final String FEATURE_FORMAT = "query(%s)";
/** To fetch model documents from Vespa index */
private final SyncSession fetchDocumentSession;
public LoadRankingmodelSearcher() {
this.fetchDocumentSession = DocumentAccess.createDefault().createSyncSession(new SyncParameters.Builder().build());
}
@Override
public Result search(Query query, Execution execution) {
// Fetch model document from Vespa
String id = String.format(VESPA_ID_FORMAT, query.getRanking().getProfile());
Document modelDoc = fetchDocumentSession.get(new DocumentId(id));
// Add it to the query
if (modelDoc != null) {
modelDoc.iterator().forEachRemaining((Map.Entry<Field, FieldValue> e) ->
addTensorFromDocumentToQuery(e.getKey().getName(), e.getValue(), query)
);
}
return execution.search(query);
}
private static void addTensorFromDocumentToQuery(String field, FieldValue value, Query query) {
if (value instanceof TensorFieldValue) {
Tensor tensor = ((TensorFieldValue) value).getTensor().get();
query.getRanking().getFeatures().put(String.format(FEATURE_FORMAT, field), tensor);
}
}
}
| The model weight document definition is added to the same content cluster as the comment documents and simply contains attribute fields for each weight and bias tensor of the neural net (where each field below is configured with “indexing: attribute | summary”): |
document rankingmodel {
field modelTimestamp type long { … }
field W_0 type tensor(x[9],hidden[9]) { … }
field b_0 type tensor(hidden[9]) { … }
field W_1 type tensor(hidden[9],out[9]) { … }
field b_1 type tensor(out[9]) { … }
field W_out type tensor(out[9]) { … }
field b_out type tensor(out[1]) { … }
}
Since updating documents is a lightweight operation it is now possible to make frequent changes to the neural net to implement the reinforcement learning process.
Results
Switching to the neural net model with reinforcement learning has already led to a 20% increase in average dwell time. The average response time when ranking with the neural net increased to about 7 ms since the neural net model is more expensive. The response time stays low because in Vespa the neural net is evaluated on all the content nodes (partitions) in parallel. This avoids the bottleneck of sending the data for each comment to be evaluated over the network and allows increasing parallelization indefinitely by adding more content nodes.
However, evaluating the neural net for all comments for outlier articles which have hundreds of thousands of comments would still be very costly. If you read the rank profile configuration shown above, you’ll have noticed the solution to this: Two-phase ranking was used where the comments are first selected by a cheap rank function (termed freshnessRank) and the highest scoring 2000 documents (per content node) are re-ranked using the neural net. This caps the max CPU spent on evaluating the neural net per query.
Conclusion and future work
In this article I have shown how to implement a real comment serving and ranking system on Vespa. With reinforcement learning gaining popularity, the serving system needs to become a more integrated part of the machine learning stack, and by using Vespa this can be accomplished relatively easily with a standard open source technology.
The team working on this plan to expand on this work by applying it to other domains such as content recommendation, incorporating more features in a larger network, and exploring personalized comment ranking.