
Beyond Simple RAG: Crafting a Sophisticated Retail AI Assistant with Vespa and LangGraph

The rise of agentic AI applications has opened a new frontier in artificial intelligence adoption, enabling organizations to create more engaging digital experiences for their customers and users.
RAG (Retrieval Augmented Generation) agentic applications vary widely in complexity. At its most basic, a Vespa-based RAG system passes a user query to a backend, performs LLM inference on the search results using a provided prompt, and returns the final output to the user. Vespa’s RAGSearcher implements this functionality out of the box. At the more sophisticated end of the spectrum, advanced RAG applications involve query analysis, chain-of-thought planning, high-quality retrieval, and LLM reasoning to deliver comprehensive answers.
In this blog post, we demonstrate an end-to-end implementation of an agentic retail chatbot assistant that provides an advanced conversational search experience through an agentic workflow encapsulating tool usage. This application transforms the traditional tool paradigm into a multi-step process that assesses user queries, requests human feedback when necessary, and constructs precise queries based on conversation history.
Furthermore, our implementation leverages Vespa’s real-time update capabilities to simulate a dynamic retail environment where inventory levels constantly fluctuate. This critical feature helps prevent the costly “zero stock event” scenario—where customers are recommended unavailable products—a common pain point in e-commerce that leads to abandoned carts and diminished customer trust. By ensuring users are only recommended in-stock items, the system maintains customer satisfaction while maximizing conversion opportunities.
Our retail chatbot assistant can address customer inquiries autonomously through three channels: its built-in knowledge, queries to Vespa, or web searches.
Agentic Application Architecture
The following diagram illustrates the architecture of the application:
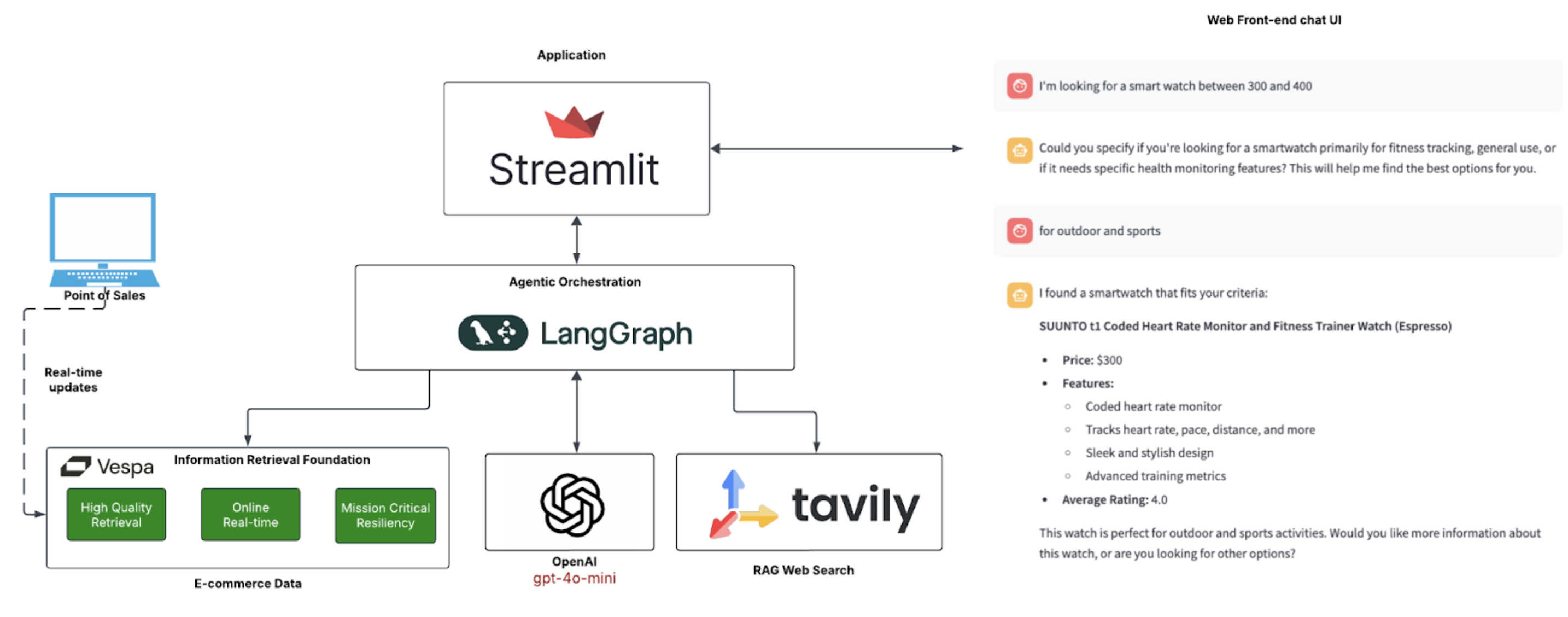
Components
Vespa
Vespa serves as our backend retrieval engine for building this real-time application. With its support for hybrid querying and ranking, Vespa enables high-quality retrieval that’s particularly well-suited for RAG agentic AI applications where retrieval quality is paramount.
We leverage the Pyvespa Python API, which facilitates rapid application development and seamless integration with LangGraph. Additionally, our application utilizes Vespa’s QueryBuilder DSL API to programmatically generate YQL hybrid queries based on conversational context, ensuring accurate results.
LangGraph
While many frameworks exist for building agentic applications, we chose LangGraph, part of the LangChain ecosystem, for this tutorial. LangGraph is designed to manage complex workflows and enables multi-step reasoning processes through its graph-based approach to AI agent orchestration.
LangChain also provides native integration with Vespa as a vector store. Integration can be achieved quite seamlessly using the Pyvespa package directly which is leveraged in this example.
Streamlit
We selected Streamlit as our UI frontend due to its rapid Python development environment for conversational applications through the st.chat API. A key advantage is its session state management, which maintains conversation context and history throughout the user session.
Tavily
The Tavily API functions as our web search engine. Designed specifically for integration with AI systems, particularly LLMs and AI agents, Tavily provides real-time information by aggregating, scoring, filtering, and ranking content from multiple online sources in a single API call.
LLM Models
In this example, we use OpenAI’s GPT-4o-mini model at different stages of the agentic workflow. This model can be substituted with alternatives as needed. Results may vary depending on the model and its parameters. A special mention to Microsoft’s Phi-4 model (14B parameters) which provided excellent results.
The Agentic Workflows
LangGraph provides a powerful framework for tool invocation within AI agents. We present two implementation examples:
Simple Application: Vespa Retriever as a Tool
Our simple application defines a web search and a Vespa Retriever. The assistant node in the graph decides which tool to invoke based on user interaction. If it chooses the VespaRetriever tool, it passes keywords to perform a semantic search on Vespa by submitting the search terms as a UserQuery. This approach is limited to keyword searches and works well for generic SEO keyword queries. The example can be modified for ANN (Approximate Nearest Neighbor) searches commonly used in RAG applications.
The diagram below shows the agentic workflow used in the application:
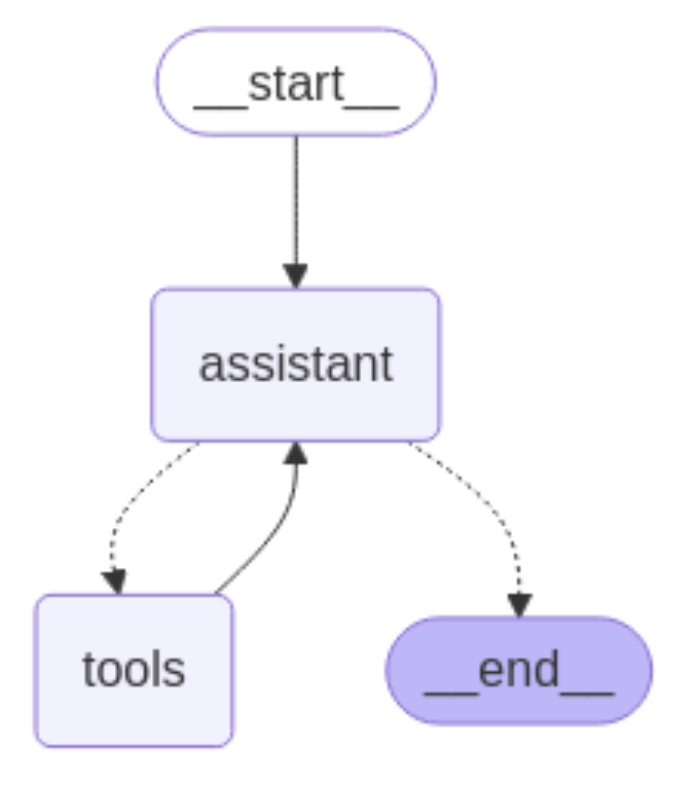
Advanced Application: Vespa Retriever as an Agent
Our more advanced application implements an agentic workflow for retrieval through Vespa.
While simple ANN searches can be performed by many vector databases, achieving high-quality retrieval requires Vespa’s hybrid queries, which combine attribute filtering, lexical search, and ANN search within a single query.
Our initial experiments leveraged a SOTA model like GPT-4o to analyze conversation history and directly generate YQL queries using few-shot examples. However, the results were inconsistent. The model occasionally missed important filters and sometimes produced syntactically incorrect queries. This experience led us to implement a more structured, multi-step approach described below:
-
Precise understanding of user needs in a conversational context. For example, if a user mentions needing “a glass”, we must determine whether they’re looking for window glass in the home improvement section or a drinking glass in the kitchen section.
-
Ability to ask clarifying questions when the information provided is insufficient. In the example above, the agent could ask the user what type of glass they’re looking for.
-
Capture of additional details from the conversation, such as price requirements, which can be passed as filters to the query.
-
Dynamic hybrid query building once the user’s requirements are fully understood.
-
Result review and reranking through an LLM before returning to the calling agent.
This sequence of steps constitutes an agentic workflow that goes beyond using Vespa as a simple tool for passing search terms.
LangGraph’s concept of subgraphs is particularly useful for implementing retriever agentic workflows. In LangGraph, a subgraph is a self-contained graph that functions as a node within a larger parent graph. In our example, a Vespa subgraph is declared as a tool used by the main agent as below:
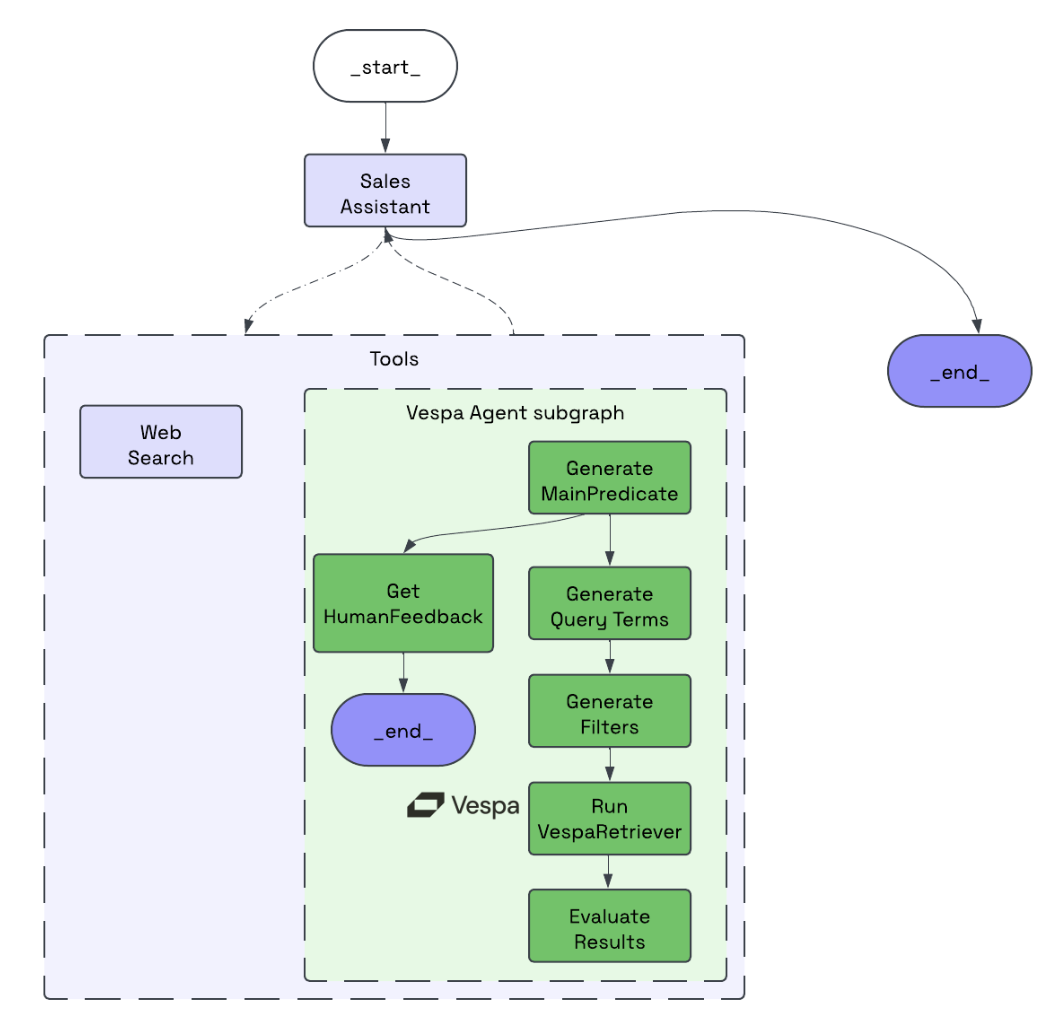
Let’s briefly examine this workflow:
-
GenerateMainPredicate: This node analyzes the chat history and user query to identify a product category. If it cannot confidently determine a category, it returns a clarifying question instead of results.
-
GenerateQueryTerms: This node refines appropriate search terms for a Vespa query based on chat history and context. These terms are used for hybrid ranking, with BM25 lexical ranking and semantic search on the item title and description.
-
GenerateFilters: This node identifies additional filters in the conversation, such as criteria for reviews or price.
-
RunVespaRetriever: Using the search terms and filters, this node leverages the VespaQueryBuilder DSL to dynamically build the YQL query and retrieve the top 10 results.
-
EvaluateResults: This step reviews the top 10 results, eliminates irrelevant records, and reranks the results through AI. This stage is ideal for AI-powered reranking, complementing Vespa’s advanced ranking features, including machine-learned ranking.
Demo
Let’s see our agentic retail assistant in action in the video below:
Tool Selection
In the demonstration, the AI agent intelligently selects the appropriate tool based on the user’s request:
- When the user asks about weather conditions or product reviews online, the AI agent leverages the web search tool to retrieve current information.
- When the user inquires about purchasing an item, the agent activates the Vespa Retriever tool.
Contextual Understanding and Clarification
Notice how the system handles ambiguity. When the user requests information about “rain gear” - a broad category - the agent recognizes the lack of specificity and asks a clarifying question. Only after receiving additional context does it match the request to an appropriate product category, enabling more precise results.
Dynamic Query Construction
After understanding the user’s needs, the application constructs this YQL query:
select id, category, title, description, average_rating, price
from product
where ((({targetHits:100}nearestNeighbor(embedding, q_embedding))
or userQuery("men's rain jacket"))
and category in ("Sports_and_Outdoors"))
and average_rating > 4.5
and quantity > 0.0
This query showcases the agentic workflow in action:
- Hybrid Search Terms: The agent derives “men’s rain jacket” as the most relevant search phrase for both lexical and semantic search components.
- Category Classification: It correctly identifies “Sports_and_Outdoors” as the appropriate category and adds it as a filter.
- Quality Filtering: The system applies additional filters for highly-rated products (average_rating > 4.5) and ensures items are in stock (quantity > 0), delivering only the most relevant and available options.
This demonstrates how the agentic application transforms a simple conversational request into a precisely structured query that leverages Vespa’s hybrid search capabilities.
Conclusion
Creating a truly conversational search experience goes far beyond implementing a simple search bar. An effective AI agent must understand user inquiries with nuance and request clarification when needed—much like the interaction you’d have with a knowledgeable store clerk. Just as a helpful retail assistant asks clarifying questions about your intent, purpose, and specific needs before making recommendations, our agentic application follows a similar human-centered approach.
The combination of LangGraph and Vespa makes this sophisticated interaction possible. LangGraph enables us to design an intuitive AI workflow that breaks the retrieval process into discrete, manageable steps—from understanding the query to delivering relevant results. Meanwhile, Vespa provides the foundation for high-quality information retrieval at scale, ensuring the most relevant items are surfaced to address user needs.
The result is a compelling and natural user experience with a virtual retail assistant capable of delivering personalized, contextually relevant help—transforming the traditional search paradigm into a truly conversational, intelligent interaction.

