
Protein models Need a PLM Store: Turning Model Outputs into Searchable Biological Intelligence- beyond LLM's
A story about bridging AI models, LIMS data, and real-world biologics discovery.
Combining variant metadata and experimental outcomes with structural embeddings enables discovery of latent relationships between sequence variants, binding sites, and design attributes in sub-seconds. When embedding meets indexing, biology becomes retrievable.
The Gen AI in Biologics: What are PLM’s?
Protein Language Models (PLMs) are reshaping how we think about biologics discovery. Models like AlphaFold-3, NextGenPLM, ESM-2, ProGen2, and Chai-1 learn the complex “grammar” of proteins — the relationships, structures, and hidden dependencies that determine how they fold, bind, and function. But while these models are becoming more capable, our infrastructure hasn’t caught up.
Most transformer-based systems today follow a feed-forward flow — they take a sequence, generate an embedding, perform a classification or prediction, and move on. The dense embedding — that high-dimensional fingerprint of biological meaning — is rarely stored or indexed. Once computed, it’s gone. As these models continue to improve, pairing them with a retrieval layer ensures their intelligence doesn’t evaporate after inference.
PLMs don’t just produce predictions; they produce representations of protein space
What is the challenge today? What do we need?
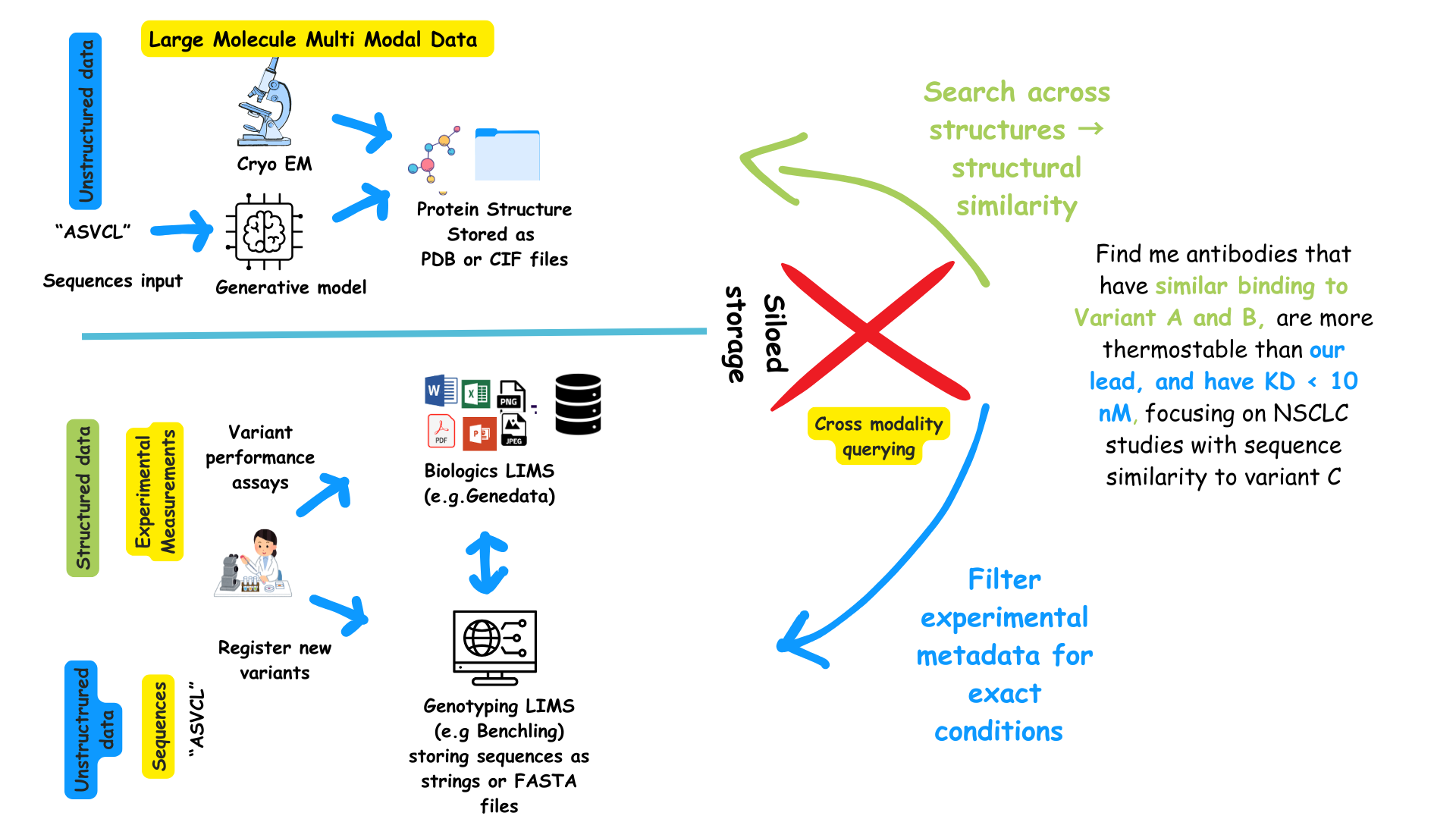
Current state in biologics development
In most pharma and biotech environments, sequence data, experimental results, and structural information live in silos:
| Data Type | System stored | Example |
|---|---|---|
| Sequences of proteins and variants | Registry or LIMS | Benchling or internal databases |
| Assay results and associated metadata e.g., Stability parameters (ΔΔG), Binding affinities (KD) or Expression yields |
LIMS / ELN | Genedata |
| 3D structures or large molecules produced - experimentally (CryoEM) or - generated via PLM’s (e.g., AlphaFold) |
Flat file store | PDB, CIF, etc. Visualized in tools like PyMOL or Chimera |
The data silo in typical biologics workflow
This generally means, you can ask questions for sequence-similar variants, or variants satisfying a certain property, but not structurally similar ones that share a given property, at least not seamlessly. For example, you cannot ask a question like:
“Show me proteins similar to antibody A, but with yields > 200 mg/L”
which combines a structural search construct (similar to Antibody A) with an experimental measurement (yield < 200mgL).
In addition, traditional sequence-based searches (like BLAST) work on sequence similarity and not on structural similarity, therefore they miss sequence dissimilar antibodies that bind to the same epitope. By contrast PLMs (AlphaFold / NextGenPLM / ESMFold, Chai-3) encode both functional and structural similarity in the vector space which can prove pivotal in finding these candidates. This will enable one to ask natural language questions like
“Find antibodies that bind similarly to a given epitope”
where the epitope input might be 3D antibody structure in a PDB format or a 2D sequence prompt which a transformer can convert to 3D.
What do we need?
We need the “PLM store” to become a memory system, a large molecule search engine — where every embedding becomes a searchable vector in a living knowledge graph of biological insight.
If we persist these embeddings (representations) — along with relevant experimental metadata from LIMS or ELN systems — we can turn one-off model outputs into a reusable, searchable atlas of biological knowledge.
Such questions however need to combine all three modalities together in a performant and cost-effective way.
Bringing this to life with an example
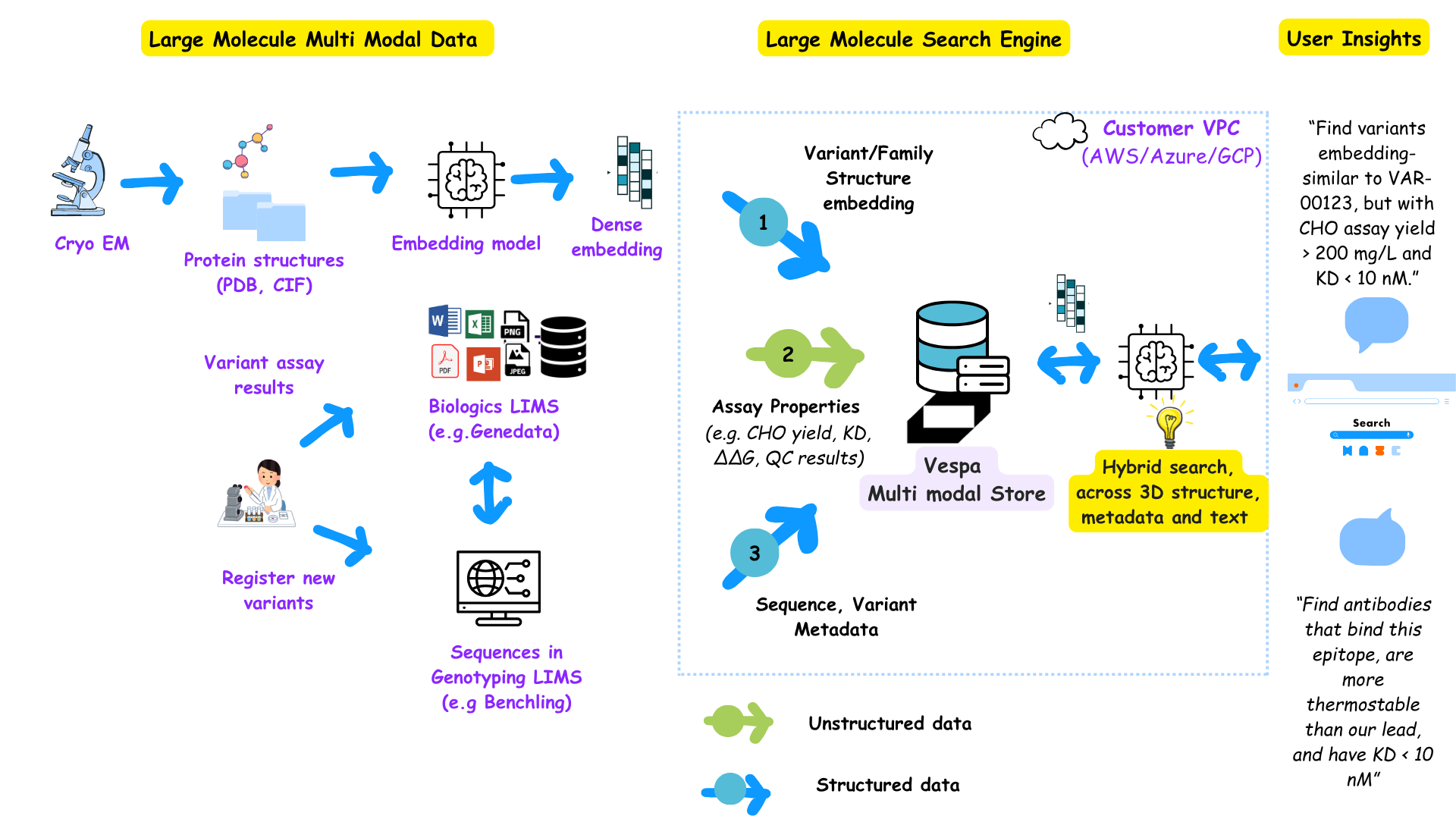 Building a biological reasoning engine with Vespa.ai (Image credit: theHGfactor.com)
Building a biological reasoning engine with Vespa.ai (Image credit: theHGfactor.com)
Consider an assay like CHO which refers to laboratory tests performed in Chinese Hamster Ovary (CHO) cells, the standard cell line used in biologics manufacturing to measure properties like protein yield, binding affinity, and stability. Let’s say you ask the question below:
“Find me antibody variants that are similar to a lead molecule, but also show higher thermostability and binding affinity below 10 nM in previous assays.”
This spans three modalities :
- vector similarity (embedding space) → from PLM’s
- structured data (stability, affinity) → from LIMS runs
- experimental metadata (variant lineage, assay source) → from database or ELN
Today it would be difficult to answer given that it needs to interrogate multi-modal data and requires hybrid retrieval (retrieval across these different modalities to tie them together). If we did build this biological reasoning engine, however, teams can avoid running isolated model inferences, and instead:
- Re-rank candidates in real time as new assays come in.
- Cross-search between antibody variants structure and metadata in a single query.
- Perform time performant alignment and discovery questions in subseconds without using a lot of compute time.
In protein discovery workflows, that means you’re not just asking “which embeddings are closest?” — you’re asking “which embeddings are closest and meet biophysical, assay, or manufacturability constraints?”
The solution: building a biological reasoning engine
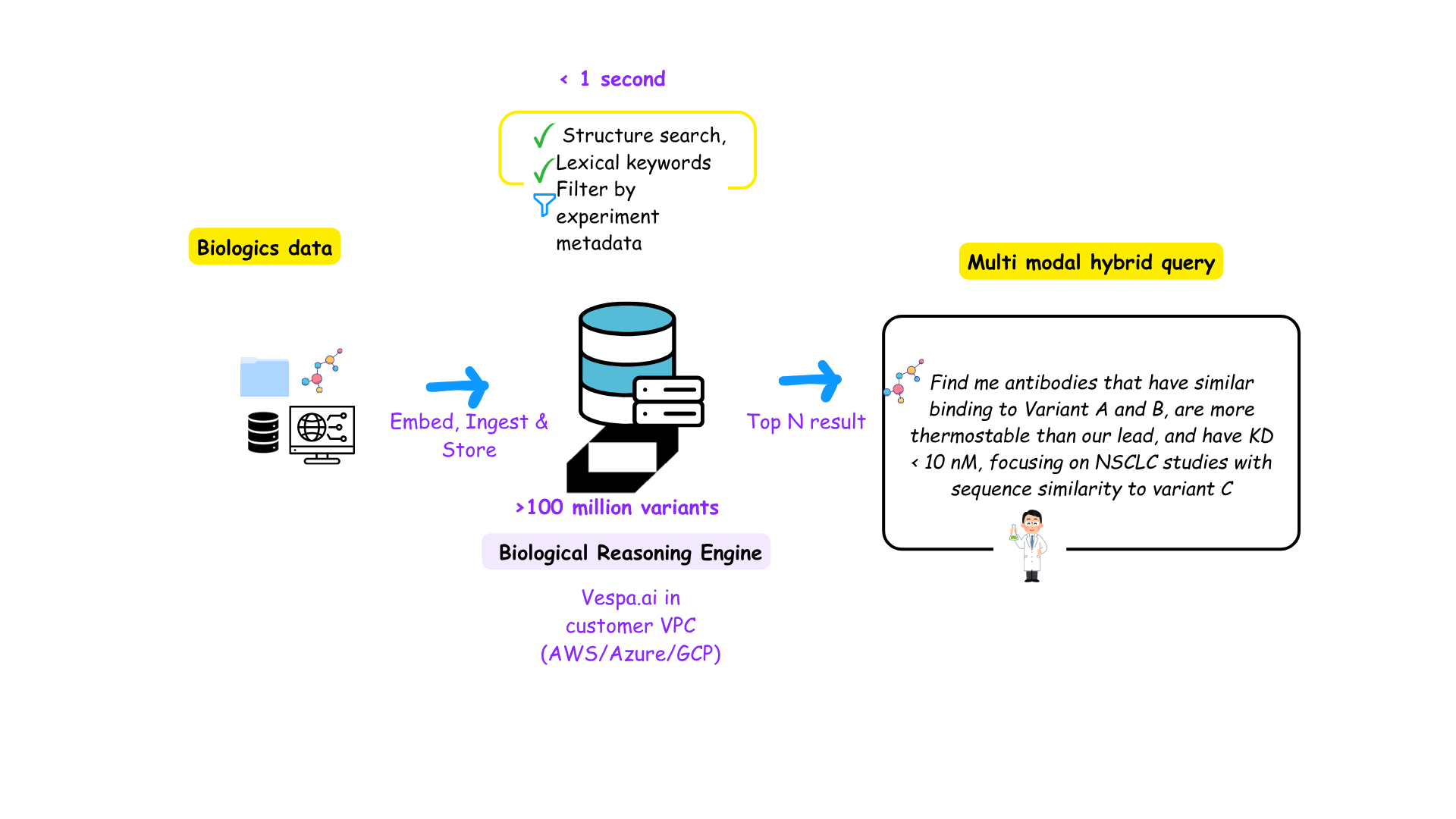 The power of hybrid retrieval (Image credit: theHGFactor)
The power of hybrid retrieval (Image credit: theHGFactor)
As mentioned earlier, what we need is a persistent store of embeddings and metadata. In addition, this needs to be indexed in a tensor-native system that can query these modalities instantaneously. This is where Vespa.ai enters the picture.
What is Vespa.ai?
Vespa.ai, a spin-off Yahoo, powers some of the bleeding edge tech like Perplexity, Yahoo, Spotify, that need retrieval at scale. It supports what we call hybrid retrieval natively since it stores vectors, numerical fields (e.g., affinity) and even unstructured annotations side by side in the same document schema. Queries can simultaneously apply structured filters, real-time ranking, and semantic similarity scoring, without moving data between systems or performing engineering after.
Vespa.ai runs on all three cloud platforms (AWS/Azure/GCP) and operates within your customer’s environment akin to other similar vector based paradigms.
Because Vespa treats tensors as first-class data types, you can directly perform mathematical operations on embeddings and metadata during ranking. This native tensor computation (ability to store multiple vectors) capability allows Vespa to handle multi-modal retrieval (e.g., protein + text + numeric context) within a single engine, eliminating the need to stitch together results post-query, which would be the case in traditional handling. This allows for more advanced and precise ranking compared to simplistic distance or other similarity metrics one might be familiar with (as seen in the below figure).
TL;DR Vespa.ai is optimized for intelligent, context-aware retrieval that scales across all modalities.
How does Vespa.ai differ from traditional vector databases?
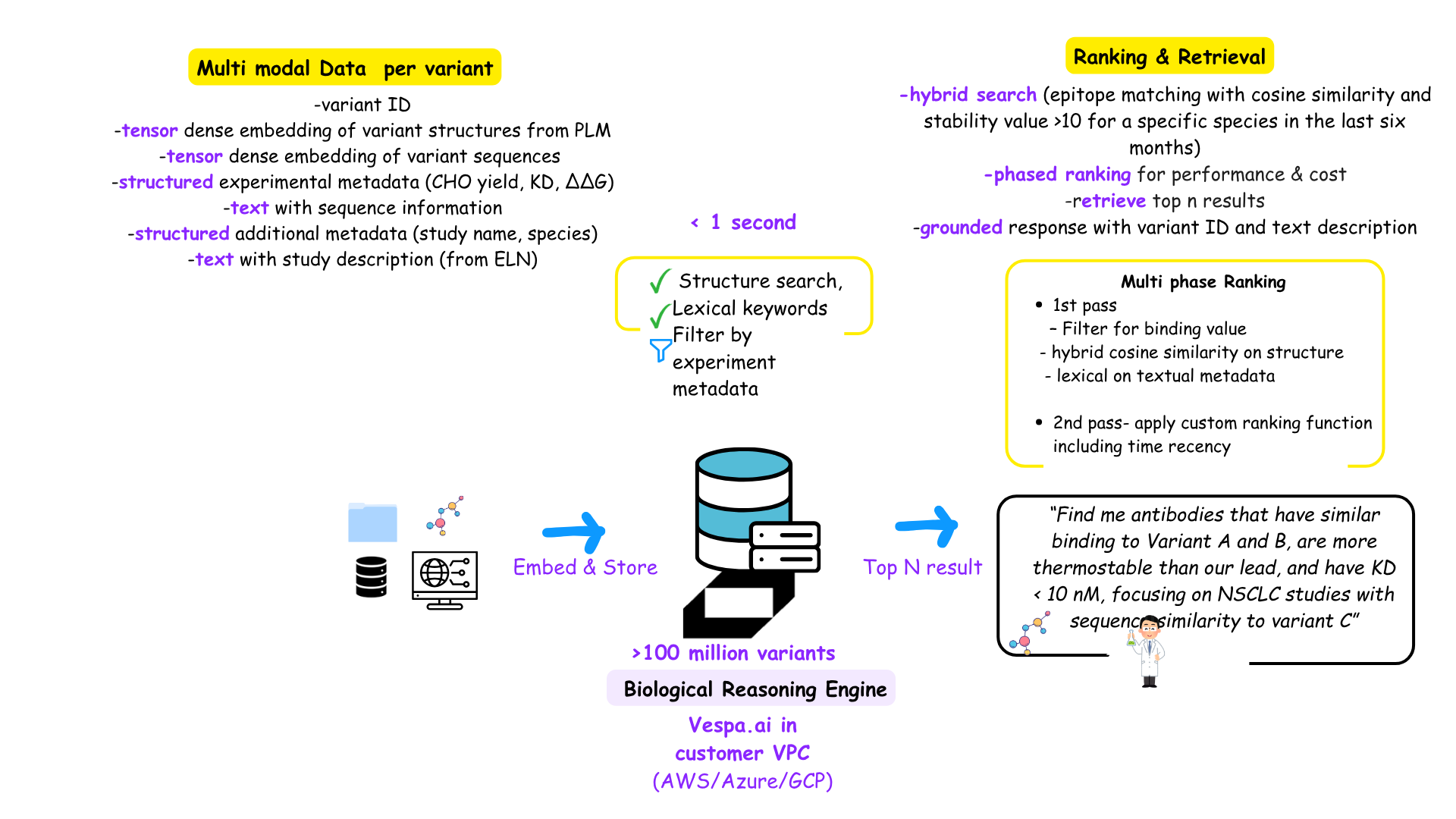 Multi modal data definition bringing multiple tensors and metadata per variant and hybrid ranking (The HGfactor)
Multi modal data definition bringing multiple tensors and metadata per variant and hybrid ranking (The HGfactor)
While traditional vector databases like Qdrant, Pinecone, or Milvus excel at approximate nearest neighbor (ANN) search, as mentioned Vespa.ai was designed from the ground up for hybrid retrieval — combining dense vector similarity, structured metadata filtering, and keyword based ranking (lexical) in a single query plan. To expand on it, traditional vector databases use a two-step pre-filter + ANN approach: structured filters are applied before vector search, and ranking is typically based on a fixed similarity metric (cosine or dot product). Some advanced ones would be able to decide the filtering strategy based on heuristics that will predicate a faster retrieval. However, they still will not be able to help with advanced scoring and ranking like what we will see below.
Let’s take the example discussed earlier where we ask the question below:
“Find me antibodies that bind this epitope, are more thermostable than our lead, and have KD < 10 nM”.
Traditional retrieval:
- We would normally eliminate the filter conditions for less than 10nM and then apply a dot product potentially to find structurally similar ones based on simple semantic scoring like L2 distance or cosine similarity.
- These also will be applied, one by one, which requires two separate retrievals and for the results to be stitched back together which ideally can be optimized in a single query plan. Additional retrieval without compromising on result quality is a way to reduce infra costs.
With Vespa.ai:
- Vespa.ai, on the other hand, executes queries through a multi-phase ranking pipeline to optimize compute costs in a single fetch.
- In the above example, Vespa.ai would perform ANN retrieval, semantic scoring and structured filtering across the data and then re-rank results using custom ranking functions, tensor expressions, or hybrid relevance models that can incorporate metadata, model confidence, or assay-derived weights to find the best candidates.
- An example of a ranking function for the above example would be like below, where the semantic similarity is multiplied with the stability and affinity scores to get the top N results.
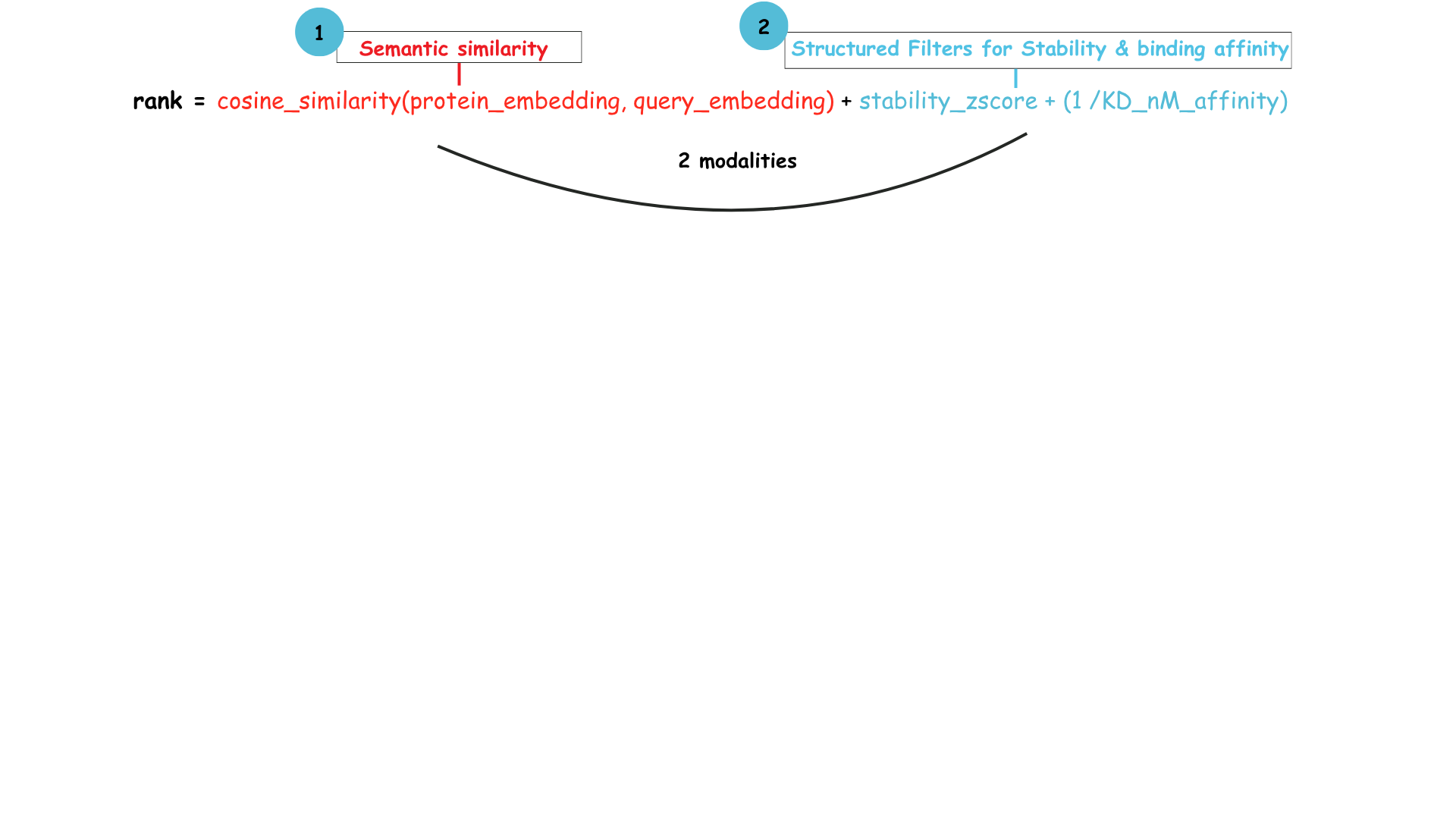
You can also extend this to include time relevancy to automatically curate it to results loaded in the last 6 months or extend it to include keyword searches from study descriptions to only fetch ones that are for a specific TA.
For example, we could rephrase the question with additional prompts and use a function like below to retrieve more accurate results:
“Find me antibodies that bind this epitope, are more thermostable than our lead, and have KD < 10 nM, with results weighted toward the latest NSCLC studies”

As seen there is no limit to the ranking profile, you could keep extending it. These complex modalities become searchable, with the ability to perform real-time ranking and retrieval under precise scientific constraints. Read more on the approaches to ranking in this RAG blueprint.
Multi vector: It isn’t just one embedding at a time
Finally, Vespa.ai supports attaching multiple vectors to the same data (Multi-vector support). Supporting multiple embedding models for your data allows you to choose the embedding model to use for the search at query time, easily test and manage vectors from multiple embedding models without having to manage duplicated metadata.
This also allows searching in different embeddings with different modalities (one embedding may encode binding compatibility, another may encode sequence similarity). You do not have to duplicate information just to attach another embedding for a variant. This can also be then added as part of retrieval function.
You can extend the above method for expressive scoring based on similarity with multiple vectors (e.g., something like one vector per potential binding site on a molecule), which allows better results for very nuanced queries. Let’s take the below example:
“Find me variants that are predicted to bind well with proteins A and B, are less thermally stable, and have sequence similarity to variant C”
Vespa.ai would execute this as well in a single query plan with a ranking function like below for getting the best top N candidates.
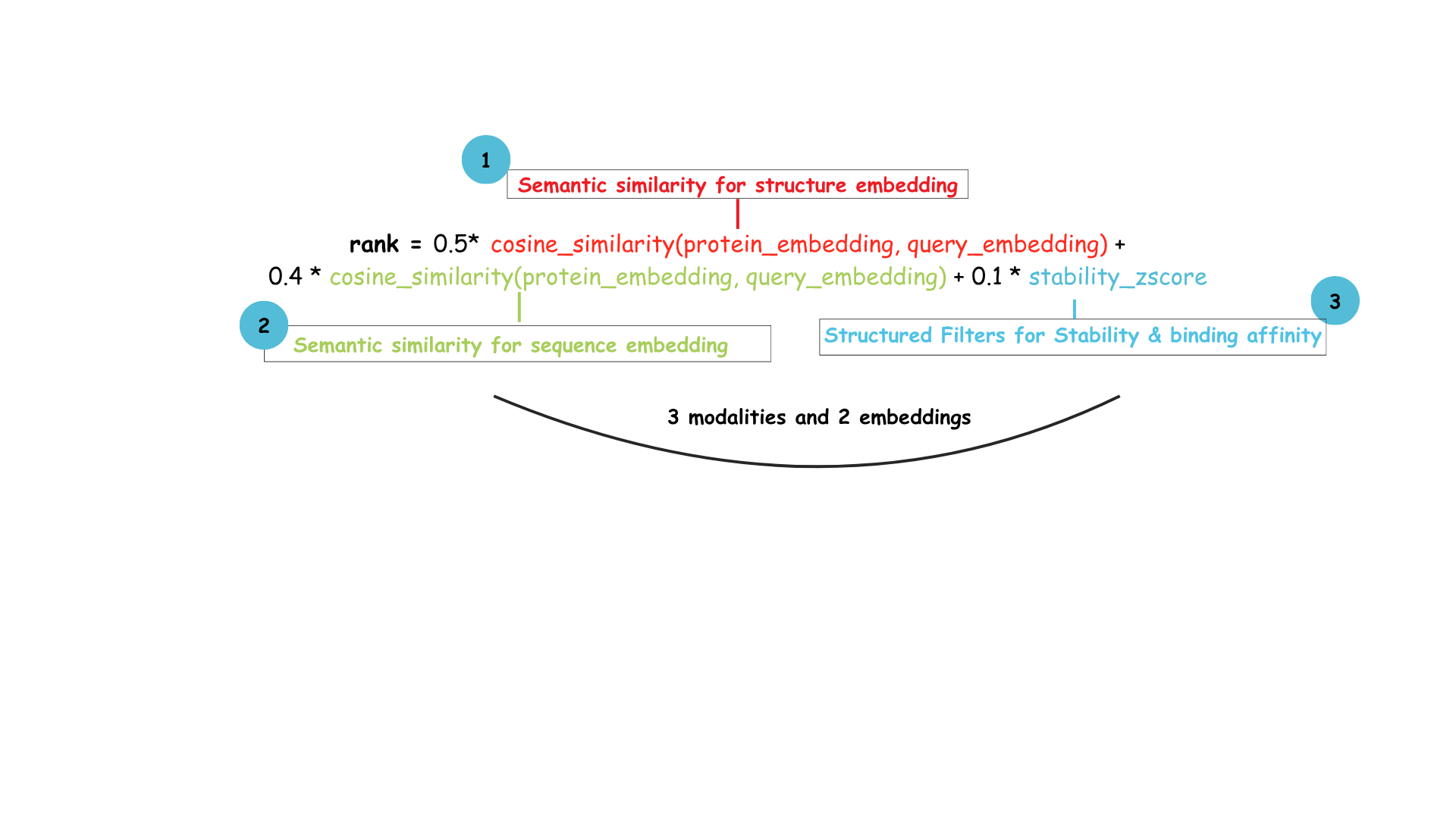
As seen above, this requires two different embeddings, one for sequence, one for structure for semantic retrieval. However, it does not require multiple retrieval at all. That is the beauty of a Vespa schema. Each variant can have as many datatypes as it wants and any number of embeddings, text, metadata or structured variables to define it.
For life sciences teams, where the right answer depends not only on similarity but also on biological constraints, Vespa.ai offers both the precision of ranking and the context of hybrid reasoning — all in one retrieval pass.
What next?
Protein Language Models like NextGenPLM, ESM-2, ProGen2, and Chai-3 are teaching machines the syntax and semantics of life itself. But their full potential is only realized when we treat their embeddings not as transient outputs but allow them to be accessible and searchable for deeper insights. Because the future of AI in biology isn’t just about generating new sequences. It’s about retrieving the right ones, at the right time, with the right context.
As models grow more expressive, our infrastructure must grow more retrievable.
🚀 Embedding meets indexing. Biology meets retrieval.
Follow me on Data, AI and us for more. For more details on Vespa.ai, read here.
Vespa.ai runs on all three clouds, inside your VPC.
If interested to discuss AI use cases, please reach out harini@thehgfactor.com!
