![]()
What you get from an AI model will never be better than the information you give it to work with. That’s why teams building great AI products put at least as much effort into information retrieval as they do into the AI models themselves.
As the leading consumer AI Search company, this is certainly true at Perplexity. While everybody can use much the same models, making search work well is what truly differentiates a great product. When Perplexity wanted to tackle this problem, they turned to the only platform that would really let them do this at scale - Vespa.ai.
Modern AI Search - as any RAG application - works by analyzing the user’s request, then executing a query that will retrieve the information necessary to answer it, before giving that information to a large language model (LLM) to generate the answer. This may be done many times to solve one problem, as in deep research. Since the information used comes from the results of a search query, sources can be clearly stated to the user, which is crucial for trustworthiness.
Creating a solution that does something like this is quite easy, but making it work reliably well is incredibly hard:
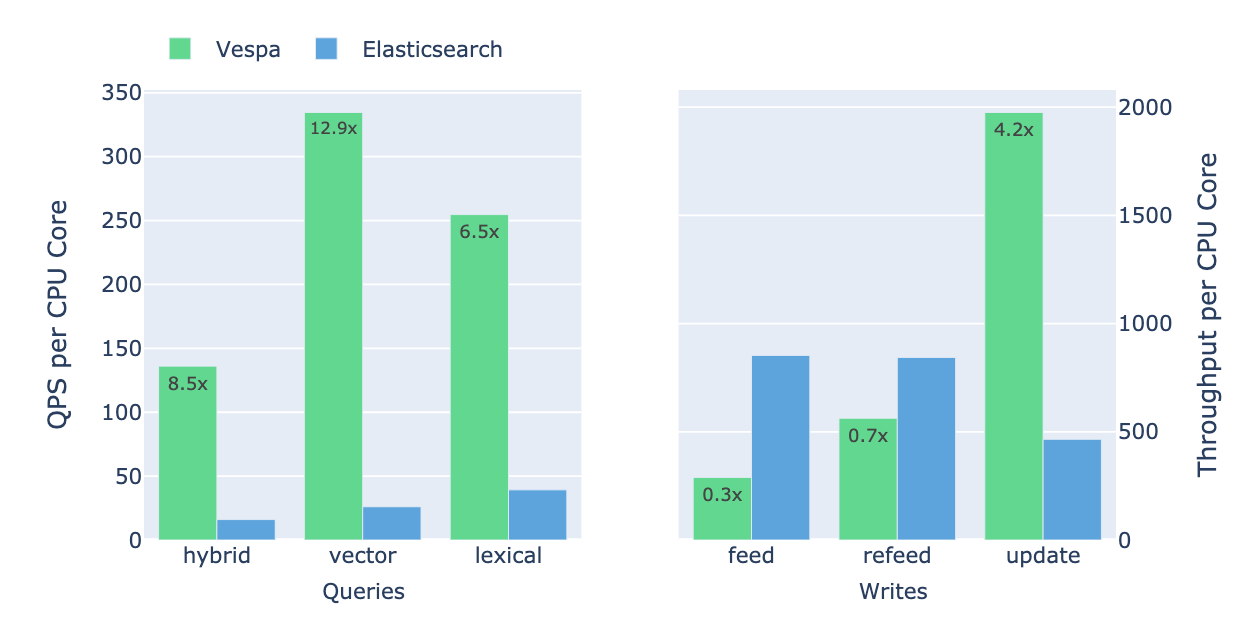
- You need to index and search enough data to cover everything the model may need to know. In Perplexity’s case this means indexing billions of web pages and attached user files.
- Each document must be stored and indexed in both textual form and as collections of vector embeddings, and together with all the relevant structured metadata and signals, updated in real time.
- All this information must be used together to find candidate documents and extract signals about the matching details, which must then be processed with tensor math and machine-learned models to determine what information should be given to the large language model to generate a response or next step.
- All of this must happen in about a hundred milliseconds, thousands of times per second.
To run this with high availability at scale, you need a distributed system running on many nodes, indexing, searching and making inferences locally. You need to develop and run many experiments with different strategies and models in parallel, deploy changes safely in production continuously, handle failing nodes, topology changes, and automated platform upgrades.
By leveraging the Vespa.ai platform, Perplexity has been able to create their own search engine that delivers uncompromising quality and performance. While this is an important milestone, we’re just getting started. We can now keep improving the usefulness of the information given to the LLMs for general and vertical tasks, which you’ll notice as Perplexity getting better and better at solving problems for you.