Optimizing realtime evaluation of neural net models on Vespa
In this blog post we describe how we recently made neural network evaluation over 20 times faster on Vespa’s tensor framework.
Vespa is the open source platform for building applications that carry out scalable real-time data processing, for instance search and recommendation systems. These require significant amounts of computation over large data sets. With advances in machine learning, it is desirable to run more advanced ranking models such as large linear or logistic regression models and artificial neural networks. Because of the tight computational budget at serving time, the evaluation of such models must be done in an efficient and scalable manner.
We introduced the tensor API to help solve such problems. The tensor API allows the concise expression of general computations on many-dimensional data, while simultaneously leaving room for deep optimizations on the platform side. What we mean by this is that the tensor API is very expressive and supports a large range of model types. The general evaluation of tensors is not necessarily efficient in all cases, so in addition to continually working to increase the baseline performance, we also perform specific optimizations for important use cases. In this blog post we will describe one such important optimization we recently did, which improved neural network evaluation performance by over 20x.
To illustrate the types of optimization we can do, consider the following tensor expression representing a dot product between vectors v1 and v2:
reduce(join(v1, v2, f(x, y)(x * y)), sum)
The dot product is calculated by multiplying the vectors together by using the join operation, then summing the elements in the vector together using the reduce operation. The result is a single scalar. A naive implementation would first calculate the join and introduce a temporary tensor before the reduce sums up the cells to a single scalar. Particularly for large tensors with many dimensions, such a temporary tensor can be large and require significant memory allocations. This is obviously not the most efficient path to calculate the resulting tensor. A general improvement would be to avoid the temporary tensor and reduce to the single scalar directly as the tensors are iterated through.
In Vespa, when ranking expressions are compiled, the abstract syntax tree (AST) is analyzed for such optimizations. When known cases are recognized, the most efficient implementation is selected. In the above example, assuming the vectors are dense and they share dimensions, Vespa has optimized hardware accelerated code for doing dot products on vectors. For sparse vectors, Vespa falls back to a implementation for weighted sets which build hash tables for efficient lookups. This method allows recognition of both large and small optimizations, from simple dot products to specialized implementations for more advanced ranking models. Vespa currently has a few optimizations implemented, and we are adding more as important use cases arise.
We recently set out to improve the performance of evaluating simple neural networks, a case quite similar to the one presented in the previous blog post. The ranking expression to optimize was:
macro hidden_layer() {
expression: elu(xw_plus_b(nn_input, constant(W_fc1), constant(b_fc1), x))
}
macro final_layer() {
expression: xw_plus_b(hidden_layer, constant(W_fc2), constant(b_fc2), hidden)
}
first-phase {
expression: final_layer
}
This represents a simple two-layer neural network.
Whenever a new version of Vespa is built, a large suite of integration and performance tests are run. When we want to optimize a specific use case, we first create a performance test to set a baseline. With the performance tests we get both historical graphs as well as detailed profiling information and performance statistics sampled from the system under load. This allows us to identify and optimize any bottlenecks. Also, it adds a bit of gamification to the process.
The graph below shows the performance of a test where 10 000 random documents are ranked according to the evaluation of a simple two-layer neural network:
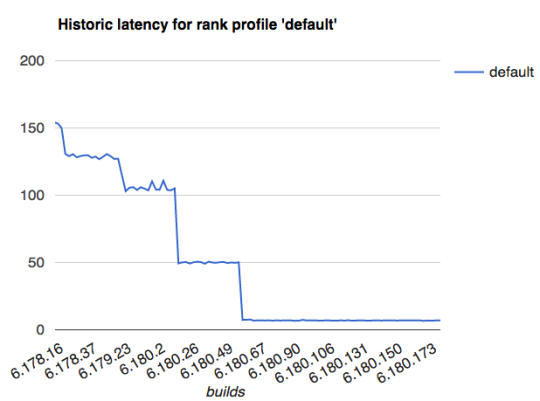
Here, the x-axis represent builds, and the y-axis is the end-to-end latency as measured from a machine firing off queries to a server running the test on Vespa. As can be seen, over the course of optimization the latency was reduced from 150-160 ms to 7 ms, an impressive 20x end-to-end latency improvement.
When a query is received by Vespa, it is first processed in the stateless container. This is usually where applications would process the query, possibly enriching it with additional information. Vespa does a bit of default work here as well, and also transforms the query a bit. For this test, no specific handling was done except this default handling. After initial processing, the query is dispatched to each node in the stateful content layer. For this test, only a single node is used in the content layer, but applications would typically have multiple. The query is processed in parallel on each node utilizing multiple cores and the ranking expression gets executed once for each document that matches the query. For this test with 10 000 documents, the ranking expression and thus the neural network gets evaluated in total 10 000 times before the top N documents are returned to the container layer.
The following steps were taken to optimize this expression, with each step visible as a step in the graph above:
- Recognize join with multiplication as part of an inner product.
- Optimize for bias addition.
- Optimize vector concatenation (which was part of the input to the neural network)
- Replace appropriate sub-expressions with the dense vector-matrix product.
It was particularly the final step which gave the biggest percent wise performance boost. The solution in total was to recognize the vector-matrix multiplication done in the neural network layer and replace that with specialized code that invokes the existing hardware accelerated dot product code. In the expression above, the operation xw_plus_b is replaced with a reduce of the multiplicative join and additive join. This is what is recognized and performed in one step instead of three.
This strategy of optimizing specific use cases allows for a more rapid application development for users of Vespa. Consider the case where some exotic model needs to be run on Vespa. Without the generic tensor API users would have to implement their own custom rank features or wait for the Vespa core developers to implement them. In contrast, with the tensor API, teams can continue their development without external dependencies to the Vespa team. If necessary, the Vespa team can in parallel implement the optimizations needed to meet performance requirements, as we did in this case with neural networks.