


Introduction
In december 2024, Answer.AI and LightOn.ai announced ModernBERT, a new and modernized version of BERT. In this blog post, we will take a look at how ModernBERT-models can be used in Vespa, improving the efficiency of your retrieval pipelines. BERT was released in 2018, and is in 2025 still one of the most downloaded models from Huggingface Hub. There have been many learnings and improvements since then, and ModernBERT’s goal was to incorporate all the learnings from the past 7 years when training a new base model.
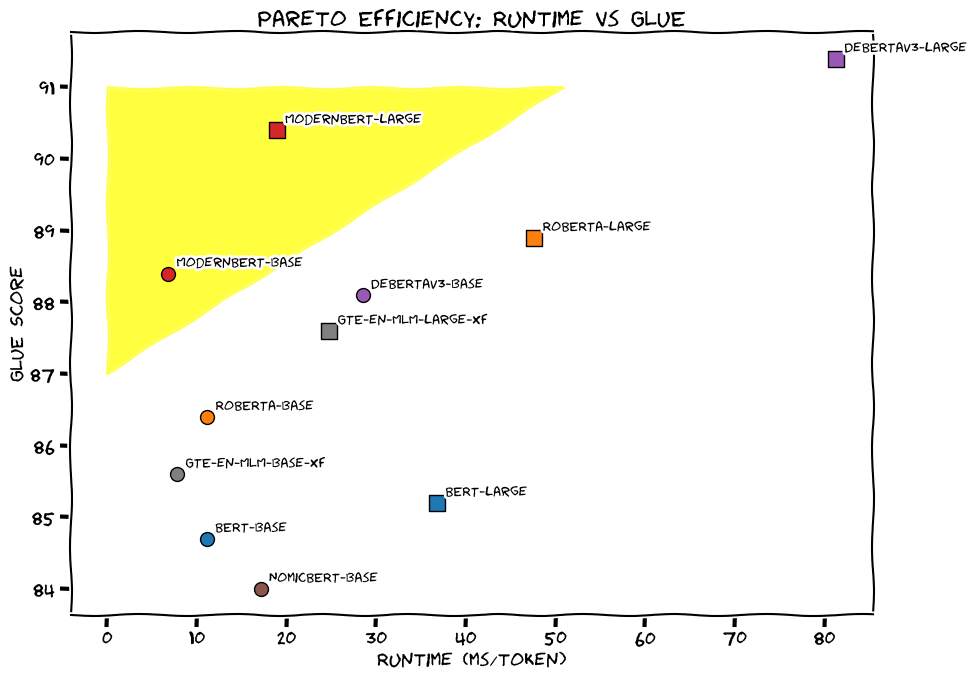
And as you can see in the image above, they succeeded. ModernBERT is a pareto improvement (both speed and performance) over BERT and its descendants.
Like BERT, ModernBERT is a base model, which is trained on the masked language model (MLM) objective. (Predict a masked token). This means that it is a general-purpose model that can (and should) be fine-tuned on a wide range of tasks, such as feature extraction (embedding), text classification, named entity recognition, and retrieval.
A couple of months after its release, we are already starting to see many fine-tuned models based on ModernBERT, and in this blog post, we will demonstrate how you can use these models in Vespa.
To view all the models that are fine-tuned on ModernBERT, you can check out its model tree at Huggingface Hub.
What’s modern about ModernBERT?
ModernBERT’s premise was to take all the recent learnings and advancements in both architecture, training techniques and dataset curation, and incorporate them into a new bi-encoder base model with a focus on:
- A modernized Transformer architecture
- Efficiency
- Modern data scale and sources
This results in a base model with features such as:
- Longer context length: Where BERT has a maximum context length of 512 tokens, ModernBERT has a maximum context length of 8192 tokens. This means that you don’t necessarily need to chunk documents that are smaller than 8192 tokens when using ModernBERT. But be aware that just because you can stuff longer documents into a single vector representation doesn’t mean you should. Please evaluate for your specific use case.
- Supports Matryoshka: Enables choosing between accuracy/efficiency by using only a sliced dimension of the vector representation. See also Shrinking embeddings for speed and accuracy and Matryoshka embeddings in Vespa.
- Uses the tokenizer from AI2’s OLMo, which was explicitly trained to model code.
- It is the first bi-encoder model to have a lot of code in the training data.
Use cases
There are two cases in particular where we think ModernBERT will shine:
1. Code retrieval
… out of all the existing open source encoders, ModernBERT is in a class of its own on programming-related tasks. We’re particularly interested in what downstream uses this will lead to, in terms of improving programming assistants.
Thanks to a code-friendly tokenizer, and the inclusion of code data in its training mixture, ModernBERT excels at code retrieval tasks. For example, gte-modernbert-base displays an incredible 79.31 average ndcg@10 on the CoIR-benchmark.

As you can see in the image above, the ModernBERT tokenizer tokenizes code in a more logical way than the other two tokenizers. 4 and 8 whitespaces are different tokens.
2. Long context retrieval
ModernBERT shows superior performance on long context retrieval tasks, such as the MLDR and LoCo benchmarks.

We were particularly impressed by the ColBERT (late interaction) version of ModernBERT’s great performance on the MLDR-benchmark. We hope (and expect) to see some “semi-official” “ColModernBERT” models soon, and will be sure to add them to our Model Hub when we do.
Using ModernBERT-models in Vespa
In general, Vespa supports most embedding models that are available on Huggingface Hub out of the box, through our generic Huggingface-embedder.
There are some configurations specific to each model that is important to get right.
Below are three ModernBERT models that we have added to our Model Hub, and with their configurations:
1. Nomic AI ModernBERT
- Description: Trained from ModernBERT-base on the Nomic Embed datasets
- Tensor Definition:
tensor<float>(x[768])(supports Matryoshka:x[256]is also possible) - Distance Metric:
angular - License: apache-2.0
- Source: nomic-ai/modernbert-embed-base @ 92168cb
- Language: English
services.xml component definition:
<component id="my-embedder-id" type="hugging-face-embedder">
<transformer-model model-id="nomic-ai-modernbert"/>
<transformer-output>token_embeddings</transformer-output>
<max-tokens>8192</max-tokens>
<prepend>
<query>search_query:</query>
<document>search_document:</document>
</prepend>
</component>
2. LightOn AI ModernBERT Large
- Description: Trained from ModernBERT-large on the Nomic Embed datasets
- Tensor Definition:
tensor<float>(x[1024]) - Distance Metric:
angular - License: apache-2.0
- Source: lightonai/modernbert-embed-large @ b3a781f
- Language: English
services.xml component definition:
<component id="my-embedder-id" type="hugging-face-embedder">
<transformer-model model-id="lightonai-modernbert-large"/>
<max-tokens>8192</max-tokens>
<prepend>
<query>search_query:</query>
<document>search_document:</document>
</prepend>
</component>
3. Alibaba GTE ModernBERT
- Description: GTE model trained from ModernBERT-base
- Tensor Definition:
tensor<float>(x[768])(supports Matryoshka:x[256]is also possible) - Distance Metric:
angular - License: apache-2.0
- Source: Alibaba-NLP/gte-modernbert-base @ 3ab3f8c
- Language: English
services.xml component definition:
<component id="my-embedder-id" type="hugging-face-embedder">
<transformer-model model-id="alibaba-gte-modernbert"/>
<max-tokens>8192</max-tokens>
<pooling-strategy>cls</pooling-strategy>
</component>
Conclusion
We are excited to see what you will build with ModernBERT in Vespa. Get started with a free trial with Vespa Cloud today.
