
Hello, I am Satoshi Takatori, in charge of search-related development at Stanby. In this post, I will detail the journey of how we have addressed the challenges faced by our existing search system through migrating to Vespa. I hope this will provide valuable information for all search engineers who are considering a migration to Vespa.
This is the English version of an article originally published on the Stanby Tech Blog.
Background of Search Engine Migration
Stanby, we are a Japanese-based job search engine. We aggregate over 10 millions of job postings in Japan, adding and refreshing hundreds of thousands of new job postings every day. We primarily have two types of searches: organic (free listings) and advertisements (paid listings). Different search engines have been used for each type: LY Corporation (formerly known as Yahoo! Japan Corporation)’s Solr-based SaaS ABYSS for organic search and Elasticsearch for advertisement search. This setup has led to various challenges.
Challenges in Organic Search
The main challenges in organic search include the risk of the search engine becoming unavailable (e.g., if ABYSS’s service ends, it could halt Stanby’s services), development constraints (as ABYSS platform is SaaS, we can’t develop the engine ourselves), scaling issues (unable to adjust server numbers quickly due to contractual limitations), and a lack of accumulated knowledge and experience in search engine development and operation within Stanby.
Challenges in Advertisement Search
The challenges in advertisement search revolve around the burden of developing and maintaining in-house developed plugins for Elasticsearch to achieve desired ranking functionality. This incur needs for cluster updates for each ranking change and version updates for Elasticsearch, as well as increased infrastructure costs due to the computation demands from these plugins.
Challenges in operating two search engine platforms
Operating different search engines for organic and advertisement searches makes us face challenges, such as the inability to share implementations for accuracy improvements between the engines, doubling the learning and operational costs, and reducing time for actual search improvements.
Decision to Unify the Search Engine
To overcome these challenges, we have decided to unify our search engine under Vespa with the goals of consolidating engineering resources, accumulating deeper knowledge on information retrieval and search engines within the company, and eliminating dependencies on external systems and licenses to increase development freedom.
Selection of Search Engine
We eventually have chosen Vespa as our next search engine platform among various search engine platforms available on the market.
Characteristics of Stanby’s Search
In selecting a search engine, it is crucial to understand the current characteristics of Stanby’s search.
- Search
- High traffic: being one of the leading job search engines in Japan, with expected growth as the service expands.
- Low Latency: As Stanby’s main feature is search, any delay in displaying search results could lead to user dropout. Since advertisements are also a form of search, any latency directly impacts revenue.
- Updates
- Handling a large volume of documents, with over 10 million job listings.
- Given the nature of a job search engine, it is essential that all listings are always searchable, not just specific ones.
- Frequent registration and deletion of documents: Job listings are frequently made public or private depending on each company’s hiring status. The speed at which new job listings are reflected is crucial, especially to prevent issues during application processes, necessitating immediate updates or removals once the data is synchronized with Stanby.
- Partial updates for feature data used in machine learning are also required.
- Machine learning
- Stanby utilizes machine learning models for ranking the search results, employing GBDT models and a two-phase ranking process. Since the machine learning team and the search infrastructure team are separate, having a custom plugin for ranking would make the machine learning team dependent on the search infrastructure team. Ideally, both teams should be able to make improvements independently.
Next, we will discuss the overview and features of the Vespa search engine.
Vespa Overview
Vespa is an open-source big data serving engine, notable for its capability to apply AI to big data online. It is versatile, used not only for search but also for recommendations and conversational AI. Originally developed within Yahoo, it was open-sourced in 2017 and became an independent company in October 2023. Vespa’s extensive use in Yahoo’s search operations demonstrates its capability to handle large volumes of documents and traffic, with the ability to process 25 billion real-time queries and 75 billion write operations (updates) per day. It’s also being adopted by globally operating companies like Spotify.
Vespa Features and Characteristics
Vespa is designed for use cases requiring real-time, low-latency, and high-throughput, making it exceptionally well-suited for Stanby’s needs. It can return responses in milliseconds, maintaining consistent response times regardless of the volume of queries or data. This is achieved through parallel query execution and the use of multiple searcher threads, allowing for flexible scaling of latency in relation to throughput.
Moreover, Vespa boasts significant scalability. Its documents are managed in units called buckets, which Vespa fully controls, eliminating the need for manual sharding. This simplifies scaling operations, as adding nodes to the cluster seamlessly increases capacity. Future increases in access can easily be accommodated through scale-out.
The indexing mechanism in Vespa is optimized for low-latency updates, making it ideal for scenarios where data constantly changes. Unlike traditional search engines, which rely on merging large index segments over time—a process that can introduce significant delays—Vespa uses a different approach. It employs a mutable in-memory index in front of immutable index segments. Changes are written to an in-memory B-tree instead of index segments and merged with the immutable index in the background. This design eliminates the need to gradually increase the size of index segments, significantly reducing the occurrence of garbage collection and large memory operations. Furthermore, documents become searchable immediately after update requests are completed.
Vespa also comes with a rich set of features for machine learning, built to apply AI to big data sets. It supports various models such as ONNX, XGBoost, and LightGBM, and data types like weightedSet and tensor, enabling sophisticated ranking algorithms. Vespa allows for the configuration of ranking algorithms through rank-profiles, which are deployed directly to the Vespa cluster as configuration files. This decouples the ranking algorithm from the search query, simplifying management.
The operational aspect of Vespa is also streamlined, as it inherently includes machine learning capabilities, reducing the overhead of managing plugins or additional components.
The compatibility of Vespa’s features with Stanby’s search characteristics—such as low latency for high traffic volumes, the capability to handle a large number of document updates, and support for complex machine learning-driven ranking algorithms—made it the preferred choice for Stanby’s search engine migration.
Compatibility between Stanby’s Search and Vespa
The characteristics of Stanby’s search and the features of Vespa were compared, and the following compatibilities were identified:
- Search: Stanby requires low latency and high traffic handling capabilities. Vespa offers fast search and high scalability, which aligns well with Stanby’s needs.
- Updates: Stanby deals with a large volume of documents, requiring frequent updates. Vespa supports efficient index creation, making it suitable for scenarios where documents are constantly being updated.
- Machine Learning: Stanby utilizes machine learning models for ranking search results. Vespa comes with a rich set of machine learning features and supports the specification of ranking algorithms through rank-profiles. This allows for sophisticated ranking that can be directly deployed to the Vespa cluster, facilitating an environment where the machine learning team and search infrastructure team can operate independently.
This alignment between Stanby’s search requirements and Vespa’s capabilities led to the decision to adopt Vespa for the search engine migration. The subsequent sections will detail the migration process to Vespa.
Migration to Vespa
Investigation and Functional Verification
Firstly, we have conducted a thorough investigation to determine whether Vespa could fulfill all the current search specifications we were offering. This was crucial for assessing the feasibility of the migration. We began by diving into the official documentation to understand the features available and how they could be utilized. However, due to the extensive amount of documentation, not everything could be reviewed at once, so the process involved gradually working through the materials.
Vespa also offers an official Docker image, which simplifies the process of local testing and verification. By using this image, we could easily simulate various scenarios and queries in a local environment, allowing for easy hands-on verification of Vespa’s capabilities and performance.
Vespa Cluster Setup
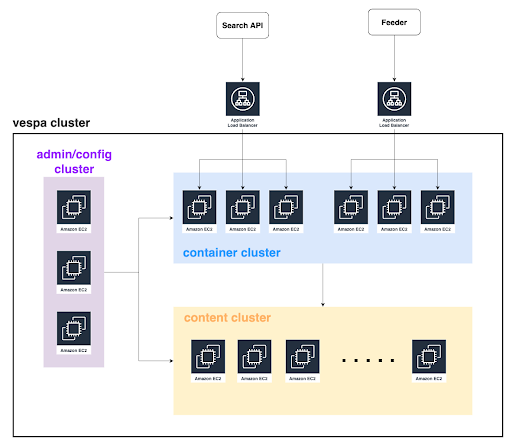
In Stanby, we set up our self-hosted Vespa cluster in AWS Tokyo Region using EC2 Instances. For high-availability (HA), a multi-node configuration is adopted, and the admin/config cluster consists of three nodes. The container cluster is separated into clusters for processing feeds and for processing search queries. This allows for changes in node performance and number according to the load for both feeds and queries, as well as preventing the load from feeds affecting searches. Since the container cluster is stateless, it is easily scalable. Different instance types are used for each cluster according to the load. Nodes in the content cluster hold data and process searches, thus using larger instance types compared to other clusters. Also, EC2 instances that have instance stores are chosen due to frequent access to disks.
Next, we will explain the method for constructing a Vespa cluster in Stanby.
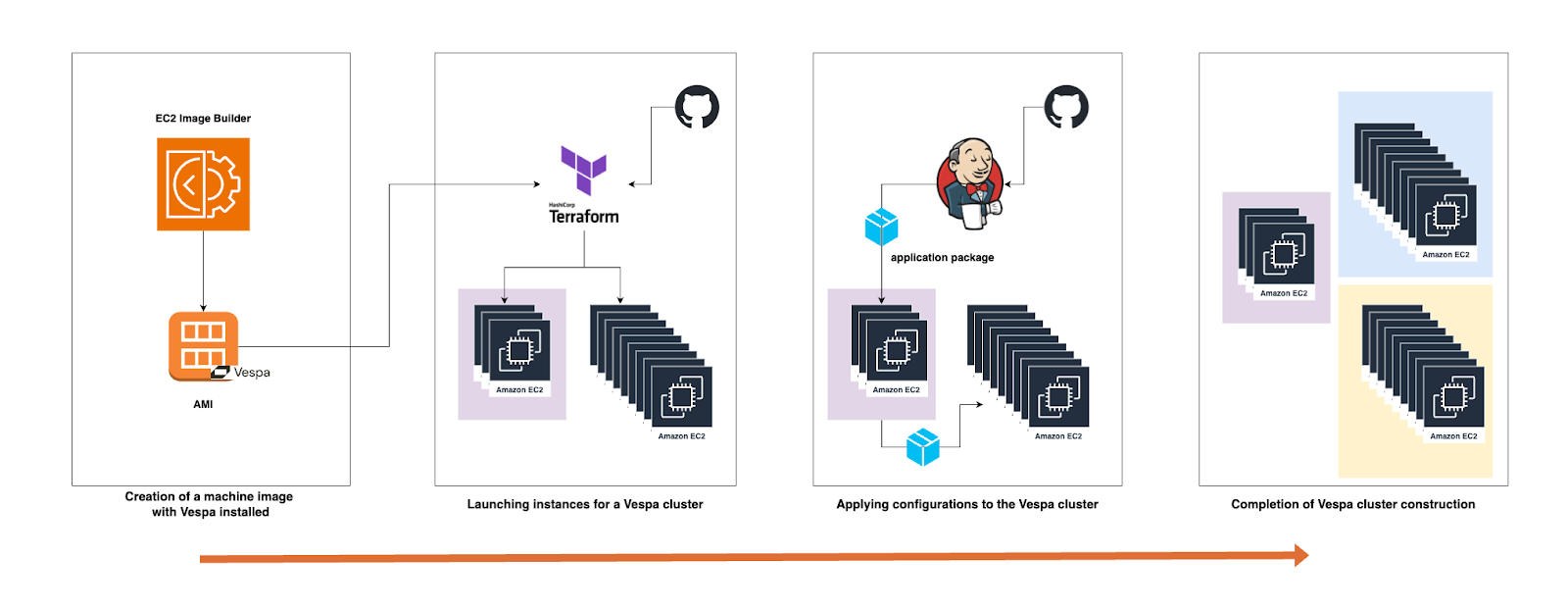
Because we have had to rebuild the Vespa cluster several times during verification on different combinations of structures and settings, we have codified the infrastructure. First, we create a machine image (AMI) with Vespa installed. We use AWS’s EC2 Image Builder to create a golden image. At this time, we also install tools necessary for monitoring and operation, such as DatadogAgent, in addition to Vespa. By preparing an AMI with Vespa installed in this way, we can shorten the instance startup time. Moreover, we can build nodes in production in exactly the same state as those verified in the verification environment, and it becomes easier to revert to a previous version of the environment.
Next, we launch instances for the Vespa cluster. The settings for the number of instances, instance type, network configuration, etc., are all managed with Terraform. Therefore, when building a new Vespa cluster, it is easy to construct by simply copying the existing settings, changing the parameters, and executing the terraform apply command. At this point, the settings for the Vespa cluster are not yet reflected, so although the Vespa process is launched on each node, they cannot operate in coordination as a cluster. It is not yet determined which node has which role. These settings are done with hosts.xml and services.xml. However, only for the config server, it is necessary to set an environment variable called VESPA_CONFIGSERVERS on all nodes. This is an environment variable for specifying the hostname of the config server that manages the Vespa configuration files. By setting this environment variable, each node connects to the config server and retrieves the configuration files.
Finally, we apply the Vespa configuration files. Vespa’s configuration files are deployed in a unit called an application package. The application package contains all settings, components, and machine learning models necessary for deployment and execution. In Stanby, we use Jenkins to create an application package from resources managed on GitHub and deploy it to Vespa.
Once the deployment of the application package is complete, each node begins to operate in coordination as a Vespa cluster.
Feature Development Overview
This section details the necessary feature development for migrating to a new search engine. The developments implemented include:
- Centralizing Query Processing:
- Initially, query transformation logic was separately implemented across Organic API, Advertisement API, and Backend API. To facilitate engine integration, we have developed a unified API for query processing.
- Search API Implementation:
- Transforms user queries into YQL.
- Developed using Rust.
- Feeder Implementation:
- Issues an update request to Vespa for each document.
- Stream processing implemented in Java.
- Linguistic Module Implementation:
- Incorporates language processing functionalities, including morphological analysis.
- Machine Learning Ranking Mode:
- Migrate the existing ranking features to Vespa compatible ones
- Offline train the ranking model using customized LightGBM framework
- Creates rank-profiles and finetune each stage in the two-phase ranking.
Linguistics
Vespa uses the Linguistics (language processing) module to process the text of documents and queries during indexing and searching.
The Linguistics module implements the following processes:
- Language identification
- Tokenizing
- Normalizing (removal of accent marks)
- Stemming
The terms resulting from these processes in the Linguistics module are added to the index. Similarly, during search, the text of the query is processed in the same way.
The Linguistics module operates within the container cluster and is implemented in Java. Although Vespa officially includes some implementations, if customization is desired, the com.yahoo.language.Linguistics interface is implemented.
For this project, we used our own implementation of the Linguistics module to allow for customization. The implementation was inspired by the following:
- SimpleLinguistics: Provides only stemming for English.
- LuceneLinguistics: Uses Lucene’s Analyzer for implementation.
- OpenNlpLinguistics: Uses OpenNLP for implementation.
- KuromojiLinguistics: Uses Kuromoji, which is made available by LY Corporation (formerly known as Yahoo! Japan), for implementation. KuromojiLinguistics, in particular, was very useful for implementing morphological analysis for Japanese.
A point of caution with Linguistics is that it identifies the language during text processing, but incorrect identification can result in mismatches. Especially for short words, such as those contained in queries, language identification can be challenging, so it is better to specify the language in search parameters. Of course, it is also important to use the same Linguistics module implementation for both search and feed.
Migration Outcomes
At present, the migration has been successfully completed for organic search, while advertisement search is still under migration.
Despite being partially migrated, the advantages of consolidating our search engine and managing it internally are significant. First, using the same search engine for both organic and advertisement searches allows us to centralize search-related resources. We are already leveraging the insights and know hows gained from the organic search to facilitate the advertisement migration.
Challenges Faced
In transitioning to Vespa, we encountered several challenges worth sharing.
Firstly, there was a significant amount of new information to learn. Vespa is fundamentally different from the search engines we had used previously, such as ABYSS and Elasticsearch, which required considerable time to understand its mechanism. While simply conducting searches could be managed by learning how to write queries, operating Vespa effectively required familiarity with a variety of its concepts. On each of Vespa’s components, multiple services operate, including proton, config-proxy, config-sentinel, config server, slobrok (Service Location Broker), and cluster controller. During operations, especially in troubleshooting, it’s essential to understand the functions of each service to identify the cause of any issues.
Additionally, the scarcity of information in Japanese posed a challenge. With limited users in Japan, there are limited resources available in Japanese. Especially for language processing aspects, we have to implement our own solutions, which require reading through code and a lot of trial and error.
Future Plans
Although the migration to Vespa is partially completed, it is just the beginning of our journey with Vespa. We plan to further utilize Vespa’s capability.
Firstly, regarding the improvement of search precision, we are considering enhancements in morphological analysis, further improvements to ranking models, vector search (ANN), and utilizing the Large Language Models. Especially noteworthy is Vespa’s capability for hybrid searches that combine conventional and vector searches, allowing us to maintain our current search specifications while integrating vector search.
Additionally, we are planning to implement auto scaling for the Vespa cluster. Given the significant fluctuations in search volume depending on the time of day in Stanby, we aim to optimize the number of instances to reduce costs. While this feature is available in Vespa Cloud, it is not provided for self-hosting, necessitating the development of an auto-scaling feature in-house.
Summary
In Stanby, we are migrating our search engine to Vespa. Having used multiple search engines previously, we decided to move to a single search engine and manage it in-house. Vespa was chosen as the unified search engine because it aligns well with the characteristics of Stanby’s search requirements. Moving forward, we plan to further leverage Vespa, including the introduction of vector search, among other enhancements.