We are excited to announce support for global significance models in Vespa. This feature improves ranking for streaming mode and ensures deterministic results in multi-node deployments using indexed mode.
Significance measures how rare a term is in a collection of documents. Rare terms, like “neurotransmitter”, are weighted higher in ranking than common terms, such as “body”. Significance is used in bm25 and nativeRank ranking functions.
By default, Vespa calculates significance values locally on each content node, based on the documents stored on that node. This makes ranking non-deterministic as the same query may be processed by different node groups or when documents are redistributed due to scaling or failure recovery. In addition, local significance is not supported in streaming search.
To address these scenarios, we introduce support for global significance models that share significance values across all content nodes, which also works in streaming search.
Example
Global significance models are specified in the significance element in services.xml:
<container version="1.0">
<search>
<significance>
<model model-id="significance-en-wikipedia-v1"/>
<model url="https://some/uri/mymodel.multilingual.json" />
<model path="models/mymodel.en.json.zst" />
</significance>
</search>
</container>
Vespa Cloud users have access to pre-built models, identified by model-id.
In addition, all users can specify their own models by providing a url to an external resource or a path to a model file within the application package.
Vespa provides a command line tool to generate model files from documents.
The order in which the models are specified determines the model precedence, see model resolution for details.
The significance feature must be also enabled in the rank-profile section of the schema:
schema example {
document example {
field content type string {
indexing: index | summary
index: enable-bm25
}
}
rank-profile default {
significance {
use-model: true
}
}
}
Experiments
We have conducted experiments to evaluate how a global significance model influences ranking quality, both in indexing and streaming search scenarios.
Three publicly available information retrieval datasets were used in these experiments:
- NFCorpus - document retrieval dataset, medical domain, 3.6K docs and 323 test queries.
- TREC-COVID - document retrieval dataset, about COVID-19, 171K docs and 50 test queries.
- MS MARCO - passage retrieval dataset, not domain specific, with ca. 8.8M docs and 7K test queries.
The global significance model was generated from English Wikipedia, which includes approximately 4.4 million articles. We compared this model to the default local model in Vespa. Our ranking expression is the sum of BM25 scores applied to a title and text fields.
The experiments were executed locally in a docker container with one content node. When running on one content node the local model is generated from all documents fed to Vespa without non-determinism due to document distribution. This corresponds to a global model generated from all documents within the collection, which is ideal for large collections. However, for streaming search, there is no local model and significance is set to a constant value.
The results are presented in the table below showing Normalized Discounted Cumulative Gain at 10 (NDCG@10) for different datasets and scenarios (indexing and streaming):
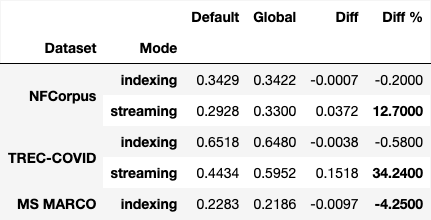
For the table we can see that the global model substantially improves streaming search. With indexing, a slight decrease in ranking scores is observed, especially in a larger, general domain dataset like MARCO. This can be mitigated by generating a model from the documents themselves, rather than relying on one built from external data.
It is worth noting that the global model incurs no performance cost for indexing and querying.
Summary
Global significance improves streaming search and provides deterministic search results in multi-node deployments. For small document collections (less than 10k documents), models generated from large external data (e.g. Wikipedia) provide good results. For larger collections, a model generated from the documents within the collection is recommended. See the significance model documentation page for details. The feature is available in Vespa as of version 8.426.8.
Got questions? Join the Vespa community in Vespa Slack.