Created by NanoBanana
Most Vespa users run hybrid search - combining BM25 (and/or other lexical features) with semantic vectors. But which embedding model should you use? And how do you balance cost, quality, and latency as you scale?
The typical approach: open the MTEB leaderboard, find the “Retrieval” column, sort descending, pick something that fits your size budget. Done, right?
Not quite. MTEB doesn’t tell you:
- How fast is inference on your actual hardware?
- What happens when you quantize the model weights?
- How much quality do you lose with binary vectors?
- Does this model even work well in a hybrid setup?
So we ran the experiments ourselves. We picked models from the MTEB Retrieval leaderboard with these criteria:
- Under 500M parameters (practical for most deployments)
- Open license
- ONNX weights available (required for Vespa)
- At least 10k downloads in the last month (actually used in production)
For each model, we benchmarked across:
- Model quantizations (FP32, FP16, INT8)
- Vector precisions (float, bfloat16, binary)
- Matryoshka dimensions (for models that support it)
- Real hardware (Graviton3, Graviton4, T4 GPU)
- Hybrid retrieval (semantic, RRF, and score normalization methods)
Spoiler: We found some really attractive tradeoffs - 32x memory reduction, 4x faster inference, with nearly identical quality.
What MTEB doesn’t show you
Model quantization
Vespa uses ONNX runtime for embedding inference. Most models on HuggingFace ship with multiple ONNX variants - here’s Alibaba-NLP/gte-modernbert-base as an example:
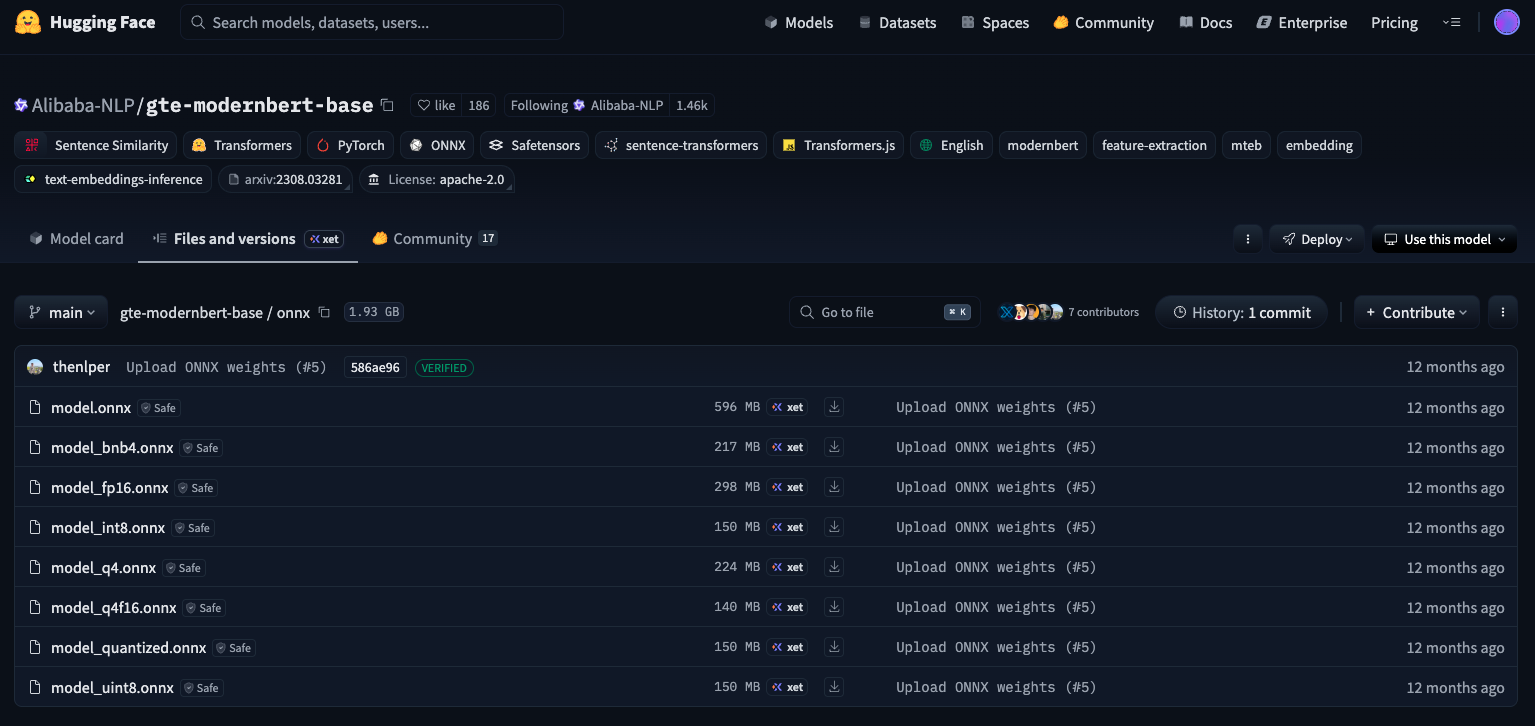
Lower precision weights = smaller model = faster inference. But how much faster, and what’s the quality hit?
- On CPU: INT8 models run 2.7-3.4x faster while keeping 94-98% of the quality
- On GPU: INT8 is actually 4-5x slower than FP32. Don’t do this.
The difference between 30ms and 100ms query latency is huge. If you’re on CPU, INT8 is often a no-brainer.
On GPU, use FP16 instead - you get ~2x speedup with no meaningful quality loss.
GPU vs CPU: The T4 GPU runs 4-7x faster than Graviton3 for embedding inference. If you’re processing high query volumes or doing bulk indexing, GPU may be worth it.
Vector precision
Model quantization affects inference speed. Vector precision affects storage and search speed. Different knobs, both important.
Here’s the math for 100 million 768-dimensional embeddings:
| Precision | Bytes/Dim | 100M vectors |
|---|---|---|
| FP32 | 4 | 307 GB |
| FP16 | 2 | 154 GB |
| INT8 (scalar) | 1 | 77 GB |
| Binary (packed) | 0.125 | 9.6 GB |
That’s a 32x difference between FP32 and binary. When memory is what forces you to add more nodes, this matters a lot.
bfloat16 is free: In our benchmarks, bfloat16 vectors show zero quality loss compared to FP32 - it’s a 2x storage reduction you can take without any tradeoff.
Matryoshka dimensions
Some models support Matryoshka Representation Learning (MRL) - you can truncate the embedding to fewer dimensions and still get decent results. Fewer dimensions = less storage, faster search.
Here’s EmbeddingGemma at different dimension sizes:
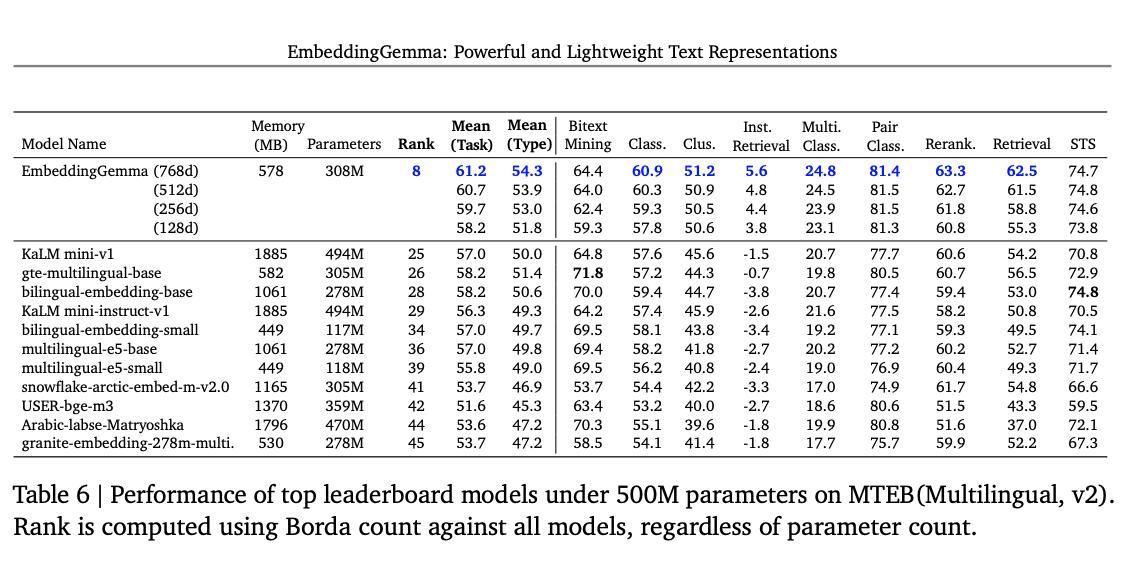
Source: EmbeddingGemma paper
Interestingly, EmbeddingGemma actually scores higher at 512 dimensions than at 768. We didn’t dig into why - it may be an artifact of the smaller evaluation set - but it’s a reminder that more dimensions isn’t always better.
Not all models support this - check the model card before truncating. If it wasn’t trained for MRL, slicing dimensions will tank your quality.
Inference speed
If you have a 200ms latency budget and your embedding model takes 150ms, you’re in trouble. We benchmarked actual inference times so you can plan accordingly.
We measured two things for each model:
- Query latency - how long to embed an 8-word query
- Document throughput - embeddings per second for 103-word docs
Tested on three AWS instance types:
c7g.2xlarge- Graviton 3 (ARM CPU)g4dn.xlarge- T4 GPUm8g.xlarge- Graviton 4 (ARM CPU)
These numbers are pure ONNX inference time. Your actual indexing throughput will also depend on HNSW config and existing index size, but embedding inference is usually the bottleneck.
Quality
We evaluated all models on NanoBEIR, a smaller but representative subset of the BEIR benchmark. This let us run a lot of experiments without waiting forever.
For each model, we measured nDCG@10 across four retrieval strategies:
- Semantic only - pure vector similarity
- RRF (Reciprocal Rank Fusion) - combines BM25 and vector rankings
- Atan hybrid - normalizes scores using arctangent before combining
- Linear hybrid - linear normalization before combining
The hybrid methods consistently outperform pure semantic search. Every single model in our benchmark scored higher with hybrid retrieval than semantic-only. On average, the best hybrid method beats semantic-only by 3-5 percentage points. That’s a meaningful lift you get “for free” by just using BM25 alongside your vectors.
We also tested each model with binarized vectors (int8). This is where things get interesting:
- ModernBERT models barely flinch - Alibaba GTE ModernBERT retains 98% of quality (0.670 binary vs 0.685 float)
- E5 models take a bigger hit - E5-base-v2 drops to 92% (0.602 binary vs 0.651 float), and E5-small-v2 to just 87%
The takeaway: not all models are created equal for binary quantization. The newer ModernBERT-based models handle it much better than the E5 family. Make sure to check before assuming you can just binarize everything.
Interactive leaderboard
We built an interactive leaderboard so you can explore the full results yourself. Filter by hardware, sort by different metrics, and expand each model to see the full breakdown across dimensions and precisions. Open in full screen.
Getting started with Vespa
Ready to put this into practice? Here’s how to configure an embedding model in Vespa:
<component id="alibaba_gte_modernbert_int8" type="hugging-face-embedder">
<transformer-model model-id="alibaba-gte-modernbert"/>
<max-tokens>8192</max-tokens>
<pooling-strategy>cls</pooling-strategy>
</component>
Here’s a schema with a binarized embedding field (96 dimensions = 768 bits packed):
schema doc {
document doc {
field id type string {
indexing: summary | attribute
}
field text type string {
indexing: index | summary
index: enable-bm25
}
}
field embedding_alibaba_gte_modernbert_int8_96_int8 type tensor<int8>(x[96]) {
indexing: input text | embed alibaba_gte_modernbert_int8 | pack_bits | index | attribute
attribute {
distance-metric: hamming
}
index {
hnsw {
max-links-per-node: 16
neighbors-to-explore-at-insert: 200
}
}
}
}
And a rank profile using linear normalization for hybrid scoring:
rank-profile hybrid_linear {
inputs {
query(q) tensor<int8>(x[96])
}
function similarity() {
expression {
1 - (distance(field, embedding_alibaba_gte_modernbert_int8_96_int8) / 768)
}
}
first-phase {
expression: similarity
}
global-phase {
expression: normalize_linear(bm25(text)) + normalize_linear(similarity)
rerank-count: 1000
}
match-features {
similarity
bm25(text)
}
}
Check out the embedding documentation for full details on configuration, including how to set up binary quantization and hybrid search.
Going further
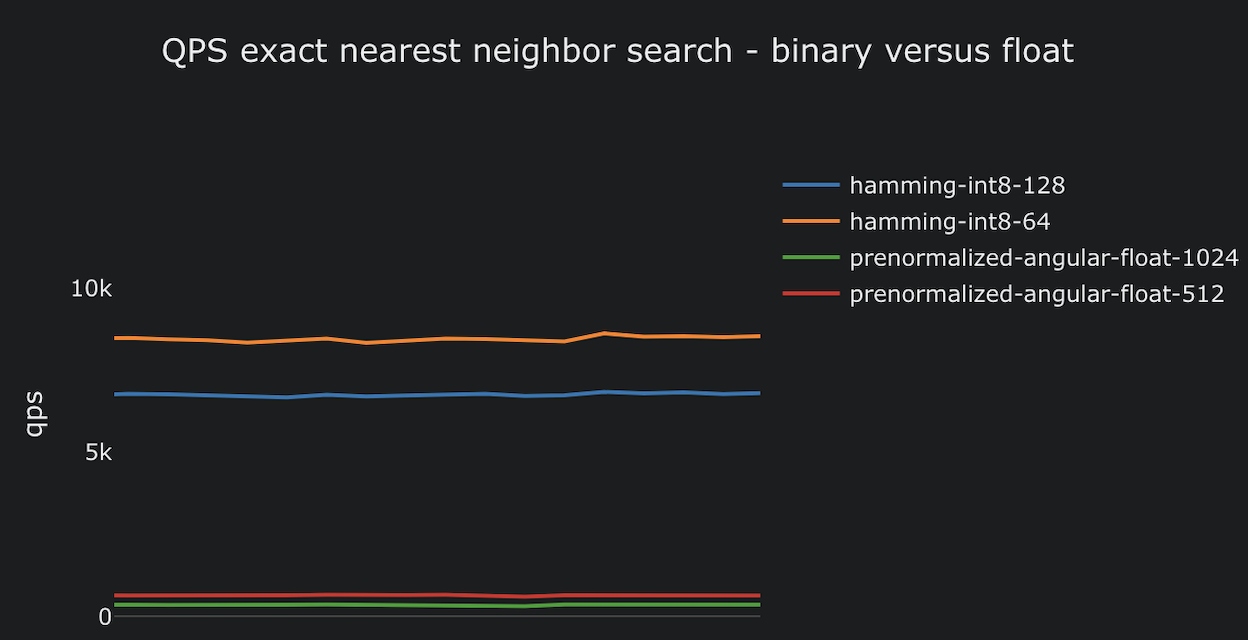
Binary vectors are fast - really fast. Vespa can do ~1 billion hamming distance calculations per second, roughly 7x more than prenormalized angular distance. That speed difference means you can crank up targetHits significantly and still stay within latency budget. More candidates evaluated = better recall. So binary vectors aren’t just about 32x storage savings - they give you headroom to tune for quality too.
And luckily, Vespa’s phased ranking architecture lets you make up for any remaining quality loss in later phases. You can retrieve candidates with hamming distance, then rescore in any of the following ways:
- float-binary - Use float for query vector, and unpack the bits of document vector to float for angular distance calculation. Example
- float-float - Retrieve with hamming distance but rerank with full-precision vectors paged in from disk. Should be limited to a small candidate set.
- int8-int8 - Same as float-float, with int8 vectors (scalar quantization, not to be confused with binary quantization) for both query and document. Faster and more storage-efficient than float-float, with a small precision cost.
See this great huggingface blog post for more details on these techniques.
For even better results, add a cross-encoder reranker as a final stage. Or (especially if you have several user signals or features), train a GBDT model to learn optimal combinations.
The beauty of Vespa’s ranking expressions is that you can mix and match all of these - BM25, a bunch of other built-in features, vectors, rerankers, learned models - however you want.
A few caveats
Multilingual support
If you need to support multiple languages, your options narrow. The multilingual-e5-base model handles 100+ languages but comes with a quality tradeoff compared to English-only models. For English-only workloads, stick with the specialized models.
Context length
Document length matters too. Many newer models handle 8192 tokens, EmbeddingGemma can take 2048, while the E5 family tops out at 512. If your documents are long, look at benchmarks like LoCo (Long Document Retrieval) - NanoBEIR won’t tell you much here.
For long documents, check out Vespa’s layered ranking - it lets you rank chunks within documents so you’re not forced to return irrelevant chunks from top-ranking docs.
Test on your own data
NanoBEIR is a good starting point, but your domain matters. A model that tops the leaderboard on scientific papers might struggle with product descriptions, legal documents, or your internal knowledge base.
Benchmark rankings can be misleading for specialized domains. The models we tested were trained on general web data - if your corpus looks very different (medical records, source code, niche industry jargon), the relative rankings might shuffle significantly.
We’ve open-sourced the benchmarking code in pyvespa so you can run the same experiments on any model with any dataset compatible with the MTEB library. Swap in your own data and see how different models actually perform for your use case.
Consider finetuning
If off-the-shelf models underperform on your domain, finetuning can help significantly. Even a small set of query-document pairs from your actual data can boost relevance.
Tools like sentence-transformers make this straightforward. The ROI is often worth it for production systems where a few percentage points of nDCG translate to real user impact.
Wrapping up
The “best” embedding model depends entirely on your constraints. But now you have real data to make that call:
- Cost sensitive? Binary quantization with a compatible model (like GTE ModernBERT) gives you 32x savings with minimal quality loss.
- Running on CPU? INT8 model quantization speeds up inference 2.7-3.4x.
- Need great quality? Alibaba GTE ModernBERT + hybrid search is hard to beat.
- Latency-critical? E5-small-v2 with INT8 can do a query inference in only 2.5ms on Graviton3.
The interactive leaderboard above has all the details. Explore, filter, and find the sweet spot for your use case.
For those interested in learning more about Vespa, join the Vespa community on Slack to exchange ideas, seek assistance from the community, or stay in the loop on the latest Vespa developments.