


Introducing Document Enrichment with Large Language Models in Vespa
Introduction
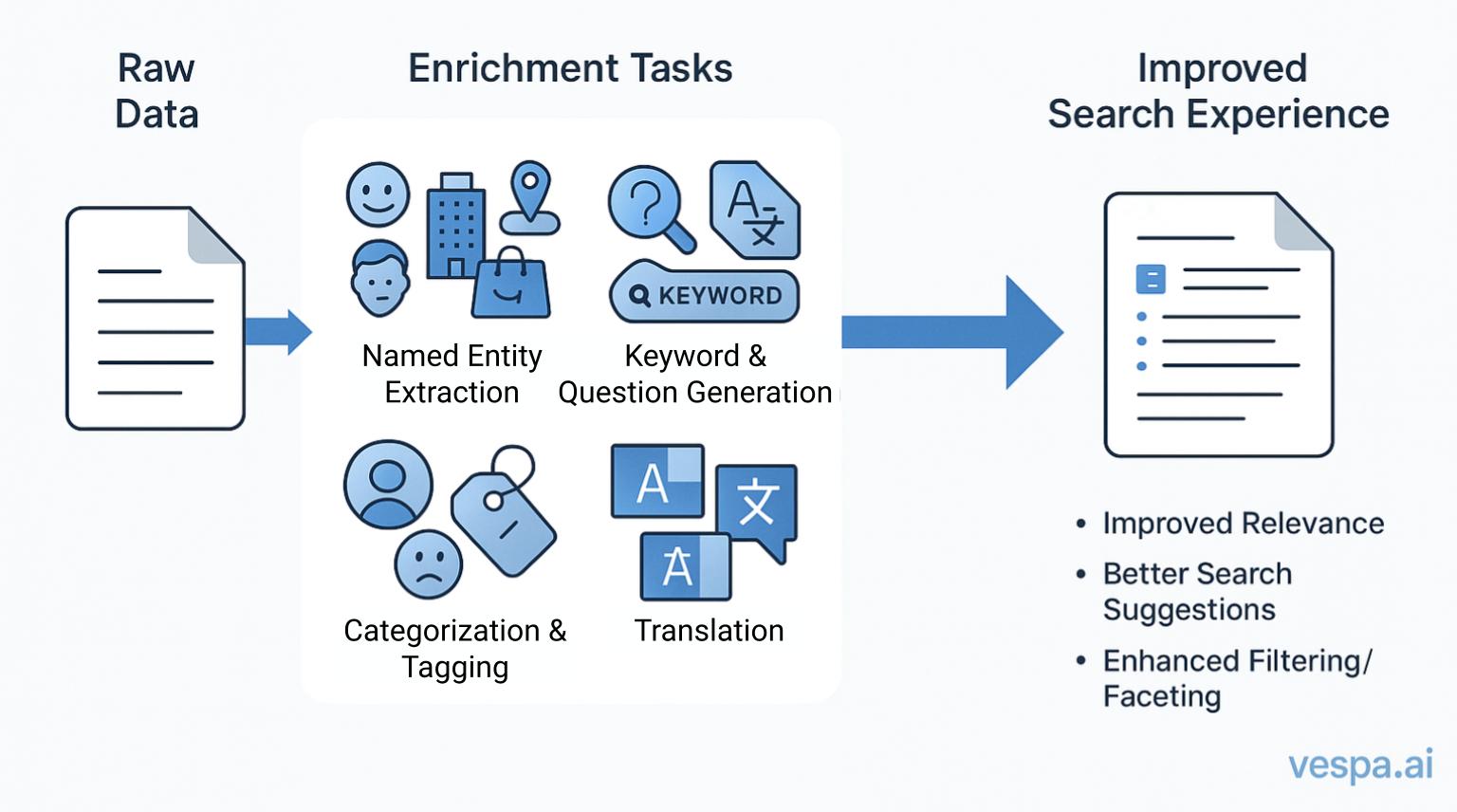
Data enrichment is the process of enhancing raw data by adding supplementary information to improve its accuracy, context, and overall value. In search applications, document enrichment can be used to transform raw text into structured form and expand it with additional contextual information. This helps to improve search relevance and create a more effective search experience. Examples of document enrichment tasks:
- Extraction of named entities (e.g., names of people, organizations, locations, and products) for fuzzy matching and customized ranking
- Categorization and tagging (e.g., sentiment and topic analysis) for filtering and faceting
- Generation of relevant keywords, queries, and questions to improve search recall and search suggestions
- Anonymization to remove personally identifiable information (PII) and reduction of bias in search results
- Translation of content for multilingual search
- Summarization for chunking and efficient retrieval
Traditionally, performing these tasks required building dedicated natural language processing (NLP) pipelines or leveraging third-party APIs. However, large language models (LLMs) have recently emerged as a viable alternative for accomplishing enrichment tasks. LLMs can perform these tasks without requiring custom code or task-specific training. The tasks are defined through prompts, which can be easily customized for a particular application.
Vespa already offers integrations with LLMs, including support for local models that run within Vespa and a client for external OpenAI-compatible APIs. In this post, we introduce a new indexing expression generate that calls an LLM during document ingestion to generate field values, using other fields as part of the prompt. Generated fields are indexed and stored as normal fields and can be used for searching without additional latency associated with LLM inference. This is a different approach to utilizing LLMs in search than retrieval-augmented generation (RAG), because RAG uses an LLM at query time to process retrieved documents.
Example
Consider the following document containing id and text fields:
schema passage {
document passage {
field id type string {
indexing: summary | attribute
}
field text type string {
indexing: summary | index
index: enable-bm25
}
}
...
}
To enrich the document, we add synthetic fields using generate:
schema passage {
document passage {
...
}
...
# Generate relevant questions to increase recall and search suggestions
field questions type array<string> {
indexing: input text | generate questions_generator | summary | index
index: enable-bm25
}
# Extract named entities for fuzzy matching with ngrams
field names type array<string> {
indexing: input text | generate names_extractor | summary | index
match {
gram
gram-size: 3
}
}
...
}
Each generate specifies a generator id, e.g. questions_generator and names_extractor.
These generators are components defined in services.xml:
<services version="1.0">
...
<container id="container" version="1.0">
...
<component id="questions_generator" class="ai.vespa.llm.generation.LanguageModelFieldGenerator">
<config name="ai.vespa.llm.generation.language-model-field-generator">
<providerId>local_llm</providerId>
<promptTemplate>Generate 3 questions relevant for this text: {input}</promptTemplate>
</config>
</component>
<component id="names_extractor" class="ai.vespa.llm.generation.LanguageModelFieldGenerator">
<config name="ai.vespa.llm.generation.language-model-field-generator">
<providerId>openai</providerId>
<promptTemplateFile>files/names_extractor.txt</promptTemplateFile>
</config>
</component>
...
</container>
...
</services>
Generators specify providerId referring to a local LLM or OpenAI client component in services.xml.
Example of a local LLM component:
<services version="1.0">
...
<container id="container" version="1.0">
...
<!-- Local language model -->
<component id="llm" class="ai.vespa.llm.clients.LocalLLM">
<config name="ai.vespa.llm.clients.llm-local-client">
<!-- Specify LLM by id for Vespa Cloud -->
<model model-id="phi-3.5-mini-q4"/>-->
<!-- Alternative is to use url, which also works outside Vespa Cloud -->
<!-- <model url="https://huggingface.co/bartowski/Phi-3.5-mini-instruct-GGUF/resolve/main/Phi-3.5-mini-instruct-Q4_K_M.gguf"/>-->
<!-- Number of tokens an LLM can attend in each inference for all parallel request. -->
<contextSize>5000</contextSize>
<!-- Requests are processed in parallel using continuous batching.
Each request will use 5000 / 5 = 1000 context tokens. -->
<parallelRequests>5</parallelRequests>
<!--Request context size split between prompt and completion tokens: 500 + 500 = 1000 -->
<maxPromptTokens>500</maxPromptTokens>
<maxTokens>500</maxTokens>
<!-- Documents will be set in a queue to wait until one of the parallel requests is done process. -->
<maxQueueSize>3</maxQueueSize>
<!-- Both enqueue and queue wait has to be set proportional to max queues size
because the last request will need to wait for all previous ones before starting the processing. -->
<maxEnqueueWait>100000</maxEnqueueWait>
<maxQueueWait>100000</maxQueueWait>
<!-- Context overflow leads to hallucinations, better to skip generation than generating nonsense. -->
<contextOverflowPolicy>DISCARD</contextOverflowPolicy>
</config>
</component>
...
</container>
...
</services>
See local LLM parameters documentation for configuration details. Example of an OpenAI client component.
<container version="1.0">
...
<container id="container" version="1.0">
...
<!-- OpenAI client -->
<component id="openai" class="ai.vespa.llm.clients.OpenAI">
<config name = "ai.vespa.llm.clients.llm-client">
<apiKeySecretName>openai-key</apiKeySecretName>
<model>gpt-4o-mini</model>
</config>
</component>
...
</container>
...
</services>
Note that OpenAI client uses an API key secret from a
secret store in Vespa Cloud.
See documentation for how to provide secrets outside Vespa Cloud.
Prompts for an LLM are constructed by combining an input of an indexing statement with a prompt template of a generator.
For example, consider the following indexing statement for the questions field:
input text | generate questions_generator | summary | index
In this case, value of the document field text will replace the {input} placeholder in the prompt template of questions_generator:
<promptTemplate>Generate 3 questions relevant for this text: {input}</promptTemplate>
Generated fields questions and names will be indexed and stored as part of the document and can be used for matching and ranking, e.g.
rank-profile with_question_and_names {
first-phase {
expression: 0.4 * nativeRank(text) + 0.1 * nativeRank(questions) + 0.5 * nativeRank(names)
}
}
Example of a retrieved document:
{
"id": "71",
"text": "Barley (Hordeum vulgare L.), a member of the grass family, is a major cereal grain. It was one of the first cultivated grains and is now grown widely. Barley grain is a staple in Tibetan cuisine and was eaten widely by peasants in Medieval Europe. Barley has also been used as animal fodder, as a source of fermentable material for beer and certain distilled beverages, and as a component of various health foods.",
"questions": [
"What are the major uses of Barley (Hordeum vulgare L.) in different cultures and regions throughout history?",
"How has the cultivation and consumption of Barley (Hordeum vulgare L.) evolved over time, from its initial cultivation to its present-day uses?",
"What role has Barley (Hordeum vulgare L.) played in traditional Tibetan cuisine and Medieval European peasant diets?"
],
"names": [
"Barley",
"Hordeum vulgare L.",
"Tibetan",
"Medieval Europe"
]
}
A complete sample application is available in sample-apps repository. You can clone and run it in Vespa Cloud or locally.
Extensibility
As usual with Vespa, existing functionality can be extended by developing custom application components. A custom generator component can be used to implement application-specific logic to construct prompts, transform and validate LLM inputs and output, combine outputs of several LLMs or use other sources such a knowledge graph. A custom language model component can be used to implement integrations with APIs that are not OpenAI-compatible. See document enrichment with LLMs and LLMs in Vespa documentation for details on implementing a custom field generator and language model components.
Hallucinations and prompt engineering
As of Q2 2025, current-generation LLMs remain susceptible to hallucinations, occasionally generating content that is factually incorrect, irrelevant to the prompt, or improperly formatted. The frequency of these errors primarily depends on the specific model used and the quality of the prompt. Generally, larger models exhibit fewer hallucinations than their smaller counterparts, but this improved accuracy comes at the cost of increased computational requirements and longer response times.
One issue we come across when using smaller LLMs is inconsistent output formatting,
which is very sensitive to minor prompt variations.
For document enrichment, consistent output formatting is crucial since prompts are automatically generated from existing document fields,
and the response must match a predefined field type (e.g., array<string>).
To ensure output consistency, we leverage structured output with constrained decoding.
This method forces LLMs to produce outputs that conform to the specified data type.
Additionally, it automatically incorporates contextual information such as a document name, field names and types
to enhance accuracy and consistency.
To get started with prompt engineering, we recommend LLM Prompting Guide from Hugging Face. It covers common NLP tasks frequently used for document enrichment.
Performance and cost
Document enrichment performance primarily depends on the underlying LLM. Application developers can choose between running local LLMs within Vespa or utilizing external LLM API providers. Performance and cost are largely determined by the model size, context size and utilized compute resources (or providers). For efficient scaling of document enrichment, it is recommended to select the smallest model and context size that delivers acceptable performance for the task at hand.
Document enrichment tasks such as information extraction, summarization, expansion and classification are often less complex than the problem-solving capabilities targeted by larger models. These tasks can be accomplished by smaller, cost-efficient models, such as Microsoft Phi-3.5-mini for a local model or GPT-4o mini for an external provider.
To give an indication of the expected performance, we measured generated fields per second (gen/sec) when ingesting 100 documents from the MS MARCO dataset into the example application described in the previous section. Each document contains approximately 70 token on average. The application schema contains two generated fields, resulting in 200 LLM calls for 100 documents. For the local model, we used Phi-3.5-mini - a 3.83 billion parameter model with 4-bit quantization. Context size is limited to 1000 tokens per call - 500 for the input and 500 for the output. Tests were conducted in Vespa Cloud with three configurations:
- Local model on CPU nodes, each with 16 cores and 32GB RAM
- Local model on GPU nodes, each with NVIDIA T4 GPUs 16GB VRAM
- OpenAI GPT‑4o mini
The corresponding results are as follows:
- Local model per CPU node: 0.1 gen/sec
- Local model per GPU node: 1.5 gen/sec
- OpenAI GPT‑4o mini: 8.6 gen/sec
Local model performance scales linearly with the number of nodes, e.g. 8 GPU nodes * 1.5 gen/sec = 12 gen/sec.
It’s important to note that GPT-4o mini is a larger and more capable model than Phi-3.5-mini. Manual inspection of the enriched documents showed the following:
- GPT-4o mini performed nearly flawlessly on the named entity recognition task, accurately extracting people, organization, and location names.
- Phi-3.5-mini successfully identified most named entities but was less accurate at following the prompt, erroneously including names of plants, medical conditions, and human organs that weren’t requested.
- Both models demonstrated strong performance in generating relevant questions
Conclusion
Document enrichment with LLMs enables a scalable application of generative AI in search that is different from RAG. It has many use cases and can both enhance retrieval on its own and serve as a complementary technique alongside RAG.
Recent advancements in LLM capabilities and efficiency enable cost-effective processing of millions of documents. As smaller models continue to improve, we expect this approach to become increasingly practical and powerful for large-scale document enrichment.
We are excited to see creative ways Vespa users will utilize document enrichment in their applications. For more information, please refer to the document enrichment documentation and sample application.