Unlocking Next-Gen RAG Applications for the Enterprise: Connecting Snowflake and Vespa.ai
From Dashboards to Agents: The RAG Revolution
Imagine a pharmaceutical company’s head of clinical development asking: “Why did enrollment drop 40% in our Q3 trials, and which patient complaints correlate with this decline?”
In the past, answering this question would require hours of work across multiple systems—querying structured databases for enrollment metrics, manually searching through unstructured patient feedback documents, and connecting insights across disparate data sources. However, as generative AI went mainstream, the once-clear delineations between descriptive, predictive, and prescriptive analytics began to blur. Traditional BI tools focused on structured data—ETL pipelines, semantic models, and dashboards. Meanwhile, AI/ML learning leaned heavily on unstructured inputs: text, images, audio, and video, and were processed by NLP models or deep learning pipelines.
But generative AI introduced a convergence with a shift towards blending the world of structured data engineers and analytics with the data scientists of the unstructured world. This shift is what led to the rise of Retrieval-Augmented Generation (RAG), which changed the dynamic entirely. Powered by the rise of RAG, both structured and unstructured data became fair game for conversational agents and copilots, which aimed to democratize institutional knowledge and reduce time to insight. Today, these agents interpret questions, access data across multiple modalities, understand relationships between entities, and surface ranked, relevant answers in milliseconds.
However, behind a sleek, conversational facade is a deeply complex architecture—stitched together with the best of analytics platforms, semantic modeling, vector representations, and transformer-based scoring engines. Let’s look at what a modern chatbot really needs as we break it down for an enterprise audience.
The State of the Stack: Structured vs. Unstructured
Let’s start by defining an agent - what’s an intelligent agent?
An intelligent agent should possess four distinct capabilities, as described below. Instead of forcing users to navigate multiple dashboards or dig through document repositories, intelligent agents should:
- Interpret natural language questions across both structured and unstructured data.
- Retrieve contextually relevant information from multiple sources.
- Ground large language model (LLM) responses in factual data.
- Provide traceable, cited answers that combine quantitative insights with qualitative context.
As stated earlier, this therefore precludes a need to manage two different modalities of data, namely:
1: Structured Data where Semantic Modeling Meets Text2SQL
Structured data, central to enterprise analytics across industries, and its integration with AI has matured rapidly, driven by advances in text-to-SQL systems. Text-to-SQL (or Text2SQL), as the name implies, is to convert text into SQL. A more academic definition would be to “convert natural language problems in the database field into structured query languages that can be executed in relational databases or warehouses”.
These systems excel when built on two pillars:
- Robust semantic models that define relationships between business entities (customers, products, time periods, geographic regions).
- Advanced text-to-SQL engines that accurately interpret natural language intent and generate precise database queries. This combination enables conversational interfaces over platforms like Snowflake, BigQuery, or Databricks—essentially creating copilots for structured data that can handle complex business questions with SQL-level precision. At the time of this writing, one of the SOTAs for textsql was Snowflake’s arctic.
2: Unstructured Data: Traditional Vector Search
Unstructured data presents a different challenge entirely. The standard approach involves broadly four steps:
- Document Processing: Breaking documents (or other modalities like images) into chunks (sentences, paragraphs, or pages for text and patches for images).
- Embedding Generation: Converting chunks into vector representations using models like OpenAI’s text-embedding-ada-002 or domain-specific alternatives.
- Indexing and Storage: Indexing embeddings for similarity search, in-memory and/or disk storage. Element-wise chunk text indexing.
- Retrieval: Finding and returning relevant chunks only, using hybrid retrieval, based on vector similarity and lexical rank features. While effective for simple text search, this traditional approach falls short for enterprise needs involving multimodal content (documents with charts, images, tables) or complex reasoning across document relationships.
The Multimodal Breakthrough: Vision-Language Models and late interaction models
What is a late interaction model?
When you’re looking for a specific answer buried deep within a dense document, a surface-level glance won’t cut it. You need a model that doesn’t just summarize or approximate—you need one that reads with the rigor of a human researcher. It’s like you skimming through every page, sentence, and word in a book to find the exact match which is also contextually relevant. That’s what a late interaction model does.
Instead of breaking an entire document into paragraphs (chunks) and embedding the chunks to vectors like traditional strategies (early interaction models), late interaction models allow every word (token) to be embedded. Then, when a user asks a question, it compares each word (token) of the question to each word (token) of the document—one by one—before deciding which result is the best match resulting in very high retrieval accuracy. Therefore, late interaction models (like ColBERT) are much better at:
- Picking up nuance in language
- Finding answers in long or complex documents
In addition, these models allow for returning results that are contextually relevant, not just “kind of similar”. Embedding models like Colbert ensure that the context of a word is taken into account so that the same word is treated differently depending on the neighbors. For example, let’s consider the use of the word “bank”, which can mean different things depending on the context, defined by its usage in a sentence. “Bank” in a “river bank” is different from “bank in a financial institution” which is different from say “Bank street” in London metro:
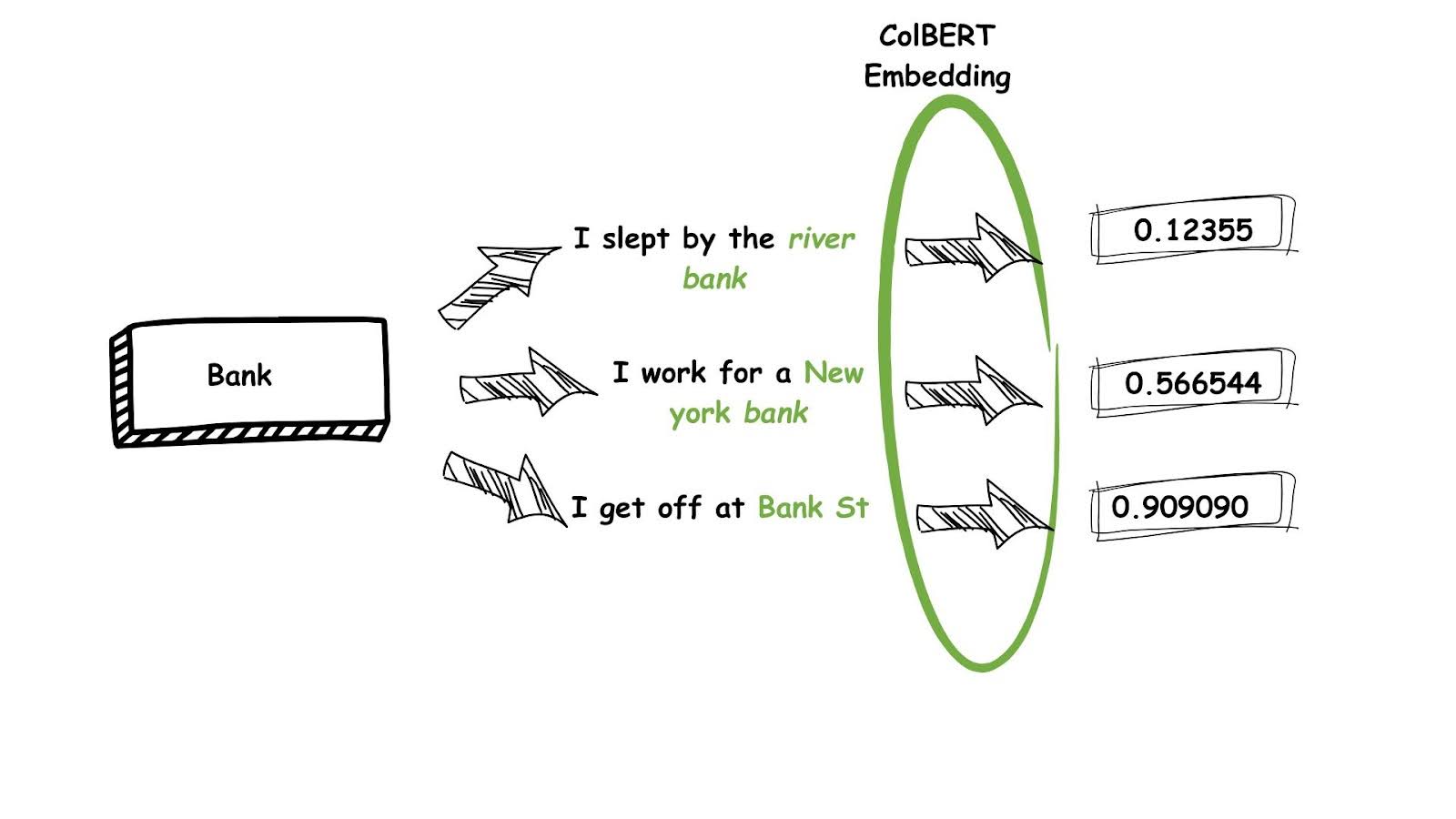
Returning the relevant results for a user question involving “bank” requires contextual understanding of the word; which in turn involves analysis of the neighboring words. This in essence is what the late interaction models do - they embed the context in addition to the word itself as depicted above.
It’s like doing a careful close reading instead of a quick glance.
The table below summarizes the differences between an early and late interaction model:
| Concept | Early Interaction | Late Interaction |
|---|---|---|
| How it searches | Looks at the summary of the document | Looks at every sentence/word |
| Speed | Faster, but less precise | Slower, but more accurate |
| Analogy | Reading the book title | Reading each chapter to find the answer |
Table 1: 🆚 Early vs. Late Interaction (Analogy)
However, this makes sense for textual content, how do we make this work when the document is multi-modal, where we have images, graphs or charts? Enter VLMs or vision language models.
What is a VLM (Vision Language Model)?
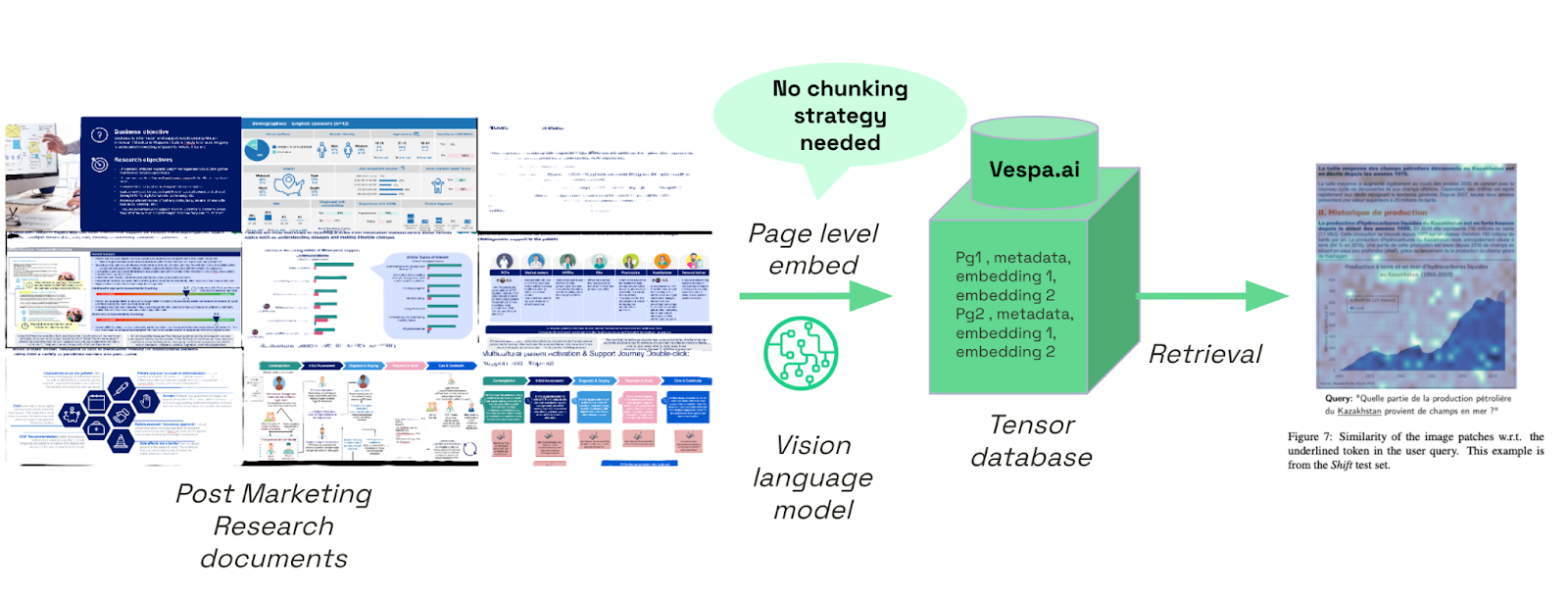
Recent advances in a family of models called vision-language models (VLMs) like PaliGemma, CLIP, GPT-4V, and other specialized document understanding models have introduced a new paradigm for unstructured data processing. Instead of fragmenting documents into text-only chunks, these VLMs can:
- Process entire pages as unified representations, capturing text, layout, images, and tables.
- Generate composite embeddings that preserve visual context and document structure.
- Reduce engineering overhead by eliminating complex pre-processing pipelines.
These models are ideal for layout-rich documents like scientific PDFs or regulatory reports, where both the text and its structure (tables, headers, visual cues) matter.
The combination of a late interaction model and VLM (models like ColPali) makes processing unstructured content really, really powerful compared to standard tensorization.
They convert complete document pages into rich, multidimensional representations—enabling more sophisticated retrieval that understands both content and context.
This also eliminates the need for complicated chunking and scoring strategies, thus simplifying the engineering effort and RAG pipeline efforts.
For the more curious, here is a great blog demonstrating ColPali in action.
Why Vespa.ai? Where does it fit?
If late interaction models and vision-language models (VLMs) significantly reduce engineering effort, why haven’t they become standard across vector databases?
The answer lies in two key challenges: technical limitations and performance overhead.
Technical Feasibility
Most vector databases are built to handle individual vectors—not tensors, which are essentially collections of vectors representing a full page. VLMs, for instance, process a document like an image, breaking it into thousands of patches (e.g., 1024 in the case of ColPali), each turned into a vector. Together, these form a tensor. Storing and manipulating such large, high-dimensional data structures requires a backend built specifically for tensor operations.
Performance Considerations
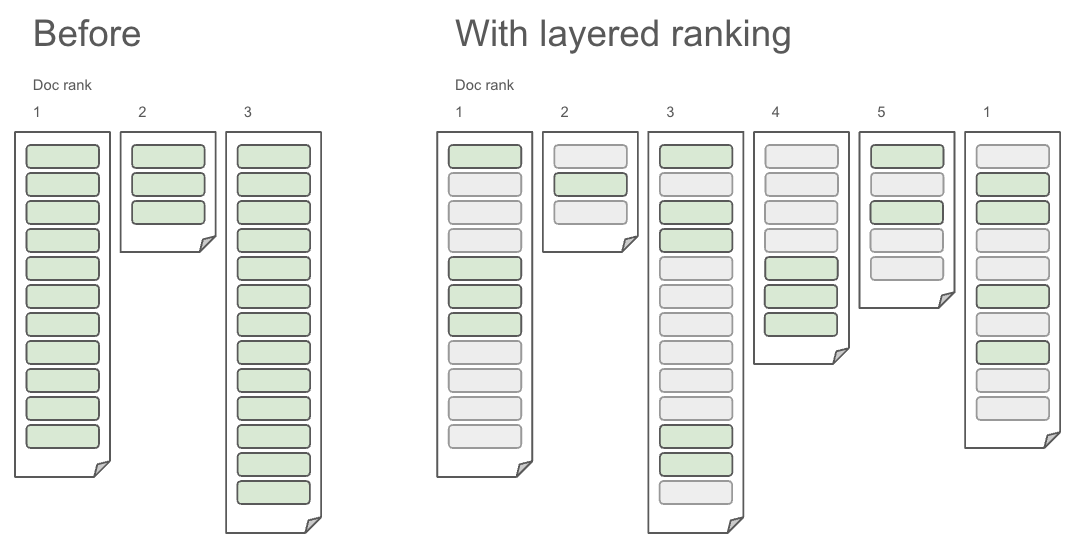
Late interaction models offer greater accuracy by comparing fine-grained relationships—such as word-to-word or patch-to-patch—across entire documents. But this comes at a computational cost. Efficiently handling this requires a multi-phase ranking system, where relevance scoring happens in stages to optimize performance without sacrificing precision.
Vespa.ai fitment
Currently, Vespa.ai is one of the only platforms that supports both these capabilities: native tensor handling and multi-phase ranking. Vespa can retain all the token-level embeddings of late interaction models and perform matching inside its engine using tensor math (consider matrix multiplication). Since it’s done in parallel, it eliminates the need for additional orchestration layers (hybrid retrieval over layout-aware tensors). Therefore, you can perform a search across keywords (structured), vector similarity (semantic) and tensor scoring (ColBERT) in a single Vespa query. With traditional vector databases, you will need to create engineering logic to perform these operations.
This makes Vespa.ai one of the most powerful techniques for enterprise-grade document search, making it the choice for management of unstructured data management at scale:
| Feature | Typical Vector DB | Vespa |
|---|---|---|
| Late interaction support | ❌ not native | ✅ tensor-native |
| Embedding per token | ❌ aggregated | ✅ retained and indexed |
| On-the-fly scoring | ❌precompute-heavy | ✅ dynamic, compiled ops |
| Hybrid search | 🟡 multi-step | ✅single-query path |
Table 2: 🆚 Vespa vs. Typical vector DB
Bringing it all together: Vespa.ai + analytics mart (Snowflake) for Advanced RAG
We have already seen that, in order to operationalize RAG in the enterprise, we needed to bring two worlds together:
-
An analytical warehouse like Snowflake to store structured facts, semantic models, and the outputs of text2SQL pipelines.
-
A tensor search engine like Vespa.ai to handle unstructured data search, multimodal embeddings, and advanced ranking.
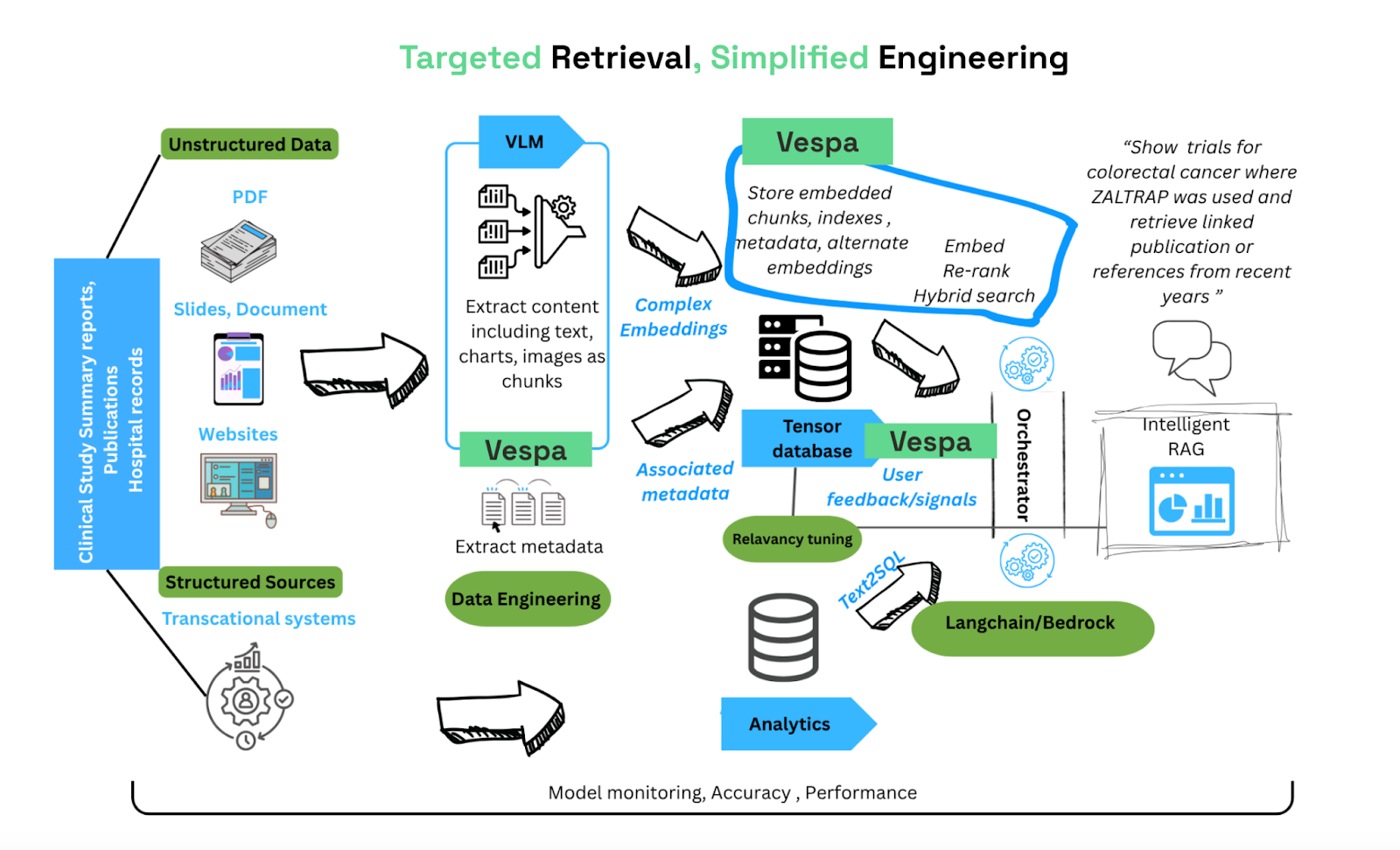
In the diagram below, we illustrate such an architecture that brings together the best of both worlds while representing Snowflake as an example for the analytics warehouse:
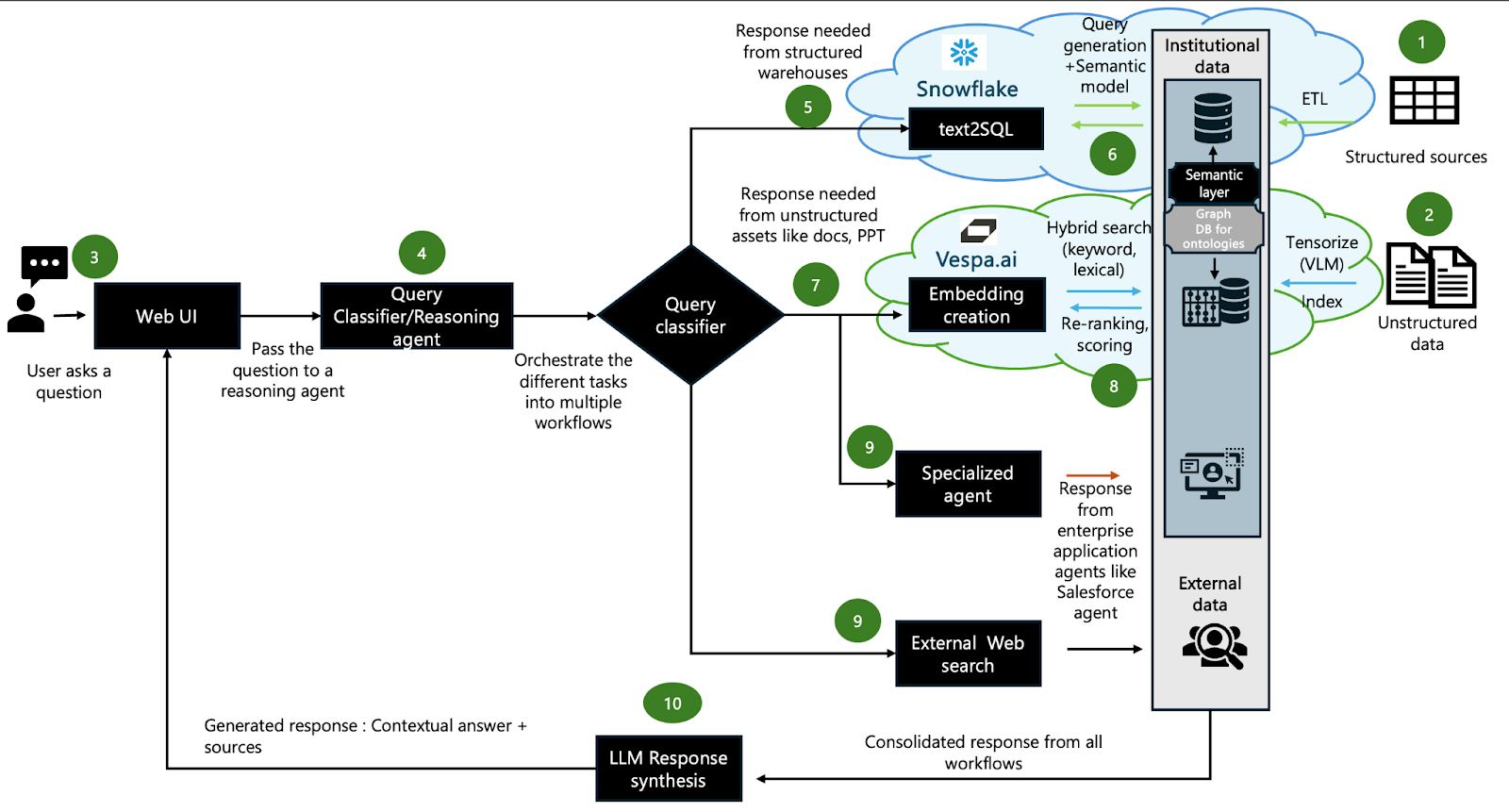 Figure 1: An end-to-end RAG application for powering intelligent search and agents
Figure 1: An end-to-end RAG application for powering intelligent search and agents
 Data processing steps delineated in Figure 1
Data processing steps delineated in Figure 1
This architecture matters because it brings about three non-tangible benefits besides accuracy and retrieval, namely:
- Performance at Scale:
- Millisecond response times for complex queries spanning multiple data sources
- Horizontal scaling to handle thousands of concurrent users
- Efficient resource utilization through specialized engines optimized for their data types
- Enterprise Security and Governance:
- Data stays within enterprise boundaries with no external API dependencies for core functionality
- Role-based access control ensuring users only see data they’re authorized to access
- Audit trails for all queries and responses supporting compliance requirements
- Cost Optimization: Rather than maintaining separate expensive systems for structured and unstructured data, the integrated approach:
- Leverages existing Snowflake investments while extending capabilities
- Reduces infrastructure complexity through purpose-built, complementary platforms
- Minimizes development overhead with proven, enterprise-ready components
Looking forward, the future of Enterprise Intelligence will evolve to look at more things like Autonomous analysis agents that proactively identify patterns and anomalies across integrated data sources, Real-time intelligence incorporating streaming data for dynamic decision support, and Industry-specific models fine-tuned for domains like healthcare, finance, and manufacturing.
Our takeaway - what’s the conclusion?
Search isn’t solved—it’s evolving. And in the age of generative AI, the enterprise search engine isn’t a single product. It’s a symphony of components: structured SQL pipelines, embedding models, multimodal chunking, tensor scoring, and fast, unified retrieval. In today’s enterprise, time-to-insight is currency. Teams don’t want to navigate ten dashboards or dig through old folders. They want answers. And to deliver those answers—grounded in truth, traceable to source, and multimodal in nature—you need an architecture that spans both the analytical and AI stack.
By integrating a best-in-class analytical platform like Snowflake with a high-performance, AI-native engine like Vespa.ai, enterprises can build the next generation of RAG systems that can finally bridge the gap between traditional analytics and modern AI capabilities.
The result isn’t just better search—it’s the foundation for truly intelligent enterprises where institutional knowledge becomes instantly accessible, questions drive insights rather than predetermined dashboards, and decision-making accelerates through AI-powered understanding.
For organizations ready to move beyond static reports and embrace conversational intelligence, the tools and architecture exist today. The question isn’t whether this transformation will happen, but how quickly forward-thinking enterprises will adopt it to gain a competitive advantage.
Ready to build your enterprise RAG architecture? Start by auditing your structured data in Snowflake and identifying high-value unstructured data sources for Vespa.ai integration. The future of enterprise intelligence is conversational—and it’s available today.
Need help? Leverage our partners to perform a quick and free discovery on the RAG architecture!