
“What’s next for AI in life sciences?” That’s a question I’ve been asking—and helping solve—through years of experience at the intersection of cloud, data, and science.
After years at the intersection of cloud, data, and science, I’ve seen firsthand the challenges life sciences organizations face when trying to extract meaningful insights from their data.
Why is Vespa.ai relevant? Read on below.
What is Vespa.ai ?
TL;DR: Vespa.ai is a high-performance engine that serves AI-powered search, recommendations, and decision-making at scale.
Search has long been a foundational capability across industries. Before the rise of large language models (LLMs), it was largely powered by systems like Elasticsearch and Solr, which focused on lexical keyword matching across documents. With the advent of LLMs, the focus shifted toward semantic search—using vector databases, embeddings, and similarity scoring (approximate Nearest Neighbor) to retrieve meaning-based results.
Vespa.ai bridges both worlds seamlessly. Vespa.ai was developed at Yahoo in 2004, and has powered massive-scale search and recommendation systems in production, including deep tensors management (complex vectors). After the spin off from Yahoo in 2023 Vespa.ai is a startup that today, powers webscale retrieval and search—the bedrock of advanced AI systems that rely on LLMs. It combines lexical and semantic search natively, enabling not only relevance from both perspectives, but also custom ranking and scoring logic during retrieval..
In short : Vespa.ai serves as a data foundation for enterprise search by excelling in four key areas
- Tensor support: natively supports the full spectrum of data—structured, unstructured, and semi-structured—within a single, unified system. Vespa.ai’s built-in tensor operations framework makes it easy to model and query this data without external tools : whether you’re working with free text, tabular data, or multi modal formats (like high dimensional embeddings of images, proteins, compounds or even a map of multiple vectors/tensors)
- Native hybrid search capability: blending both lexical (keyword-based), structured (say clinical_trial_phase>=1) and vector (semantic) search in one engin, eliminating the need to stitch together multiple components
- Custom ranking & Real time processing: And because Vespa.ai handles real-time indexing and updates with ranking optimizations, your search results reflect the latest data instantly—no lag, no batch refreshes while providing accuracy needed for ranking
- Overall ROI : and because Vespa.ai handles everything as tensors and allow multi-phase ranking, this reduces overall query costs. We will see what these terms are as we keep reading.
Together these capabilities provide a powerful foundation for building AI applications that need both accuracy and agility at scale.
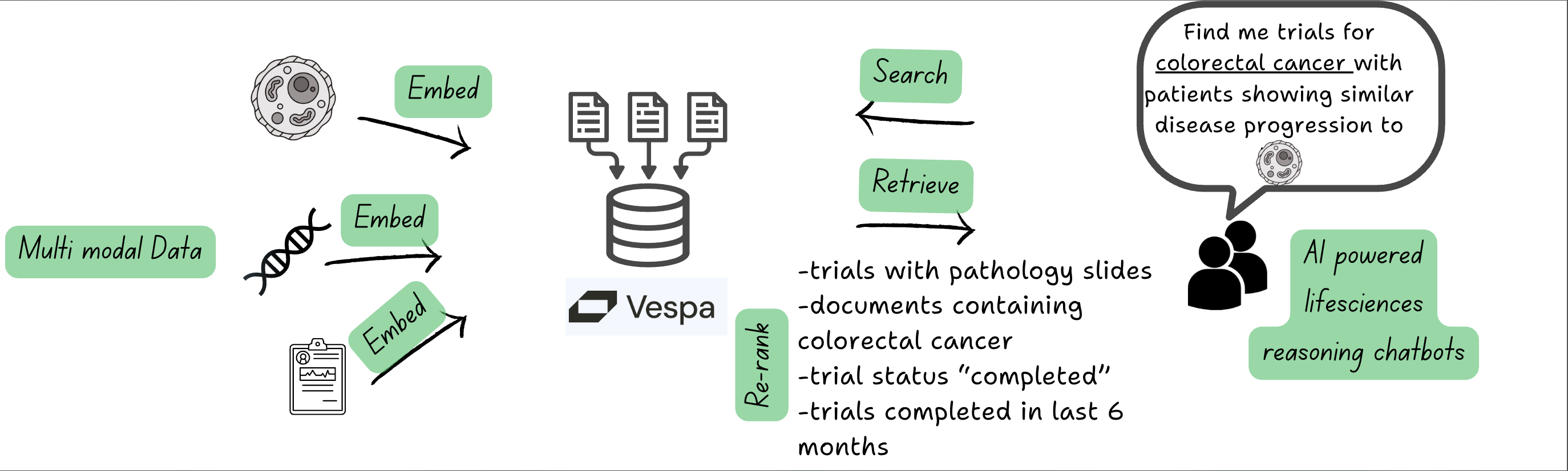
Why is it relevant for health and life sciences?
Lifesciences deal with data of different modalities that are predominantly unstructured or semi structured when it comes to AI use cases: omics, compounds, 3D structures of proteins/biologics, medical images, regulatory documents, trial designs, clinical study reports, brand campaigns and more
The key focus of these Advanced AI RAG solutions is to be able to “find” and “assemble” the “relevant” information as “quickly” as possible from these myriad of sources.
This is precisely where Vespa.ai’s ability to handle and reason over tensors in real-time excels, with its hybrid search capabilities, relevance-based ranking, and ML inference over scientific data at scale.
TL;DR: The 4 key words to retain here are “find” , “assemble” , “relevant” and “quickly”.
But before we dive deeper into applications, let’s address a fundamental question:
But what is a tensor? Why is it important for life sciences and search?
A tensor: The new age of AI - think beyond vectors
In the AI world, “tensors” are everywhere—yet rarely discussed outside deep tech circles. If you’re working in pharma, healthtech, or biotech, understanding how tensors power AI can help you better leverage technology innovation.
So what exactly is a tensor? Think of it as a multi-dimensional data container—an evolution of the tables and matrices we’re used to. While vectors are one-dimensional arrays and matrices are two-dimensional, tensors take this to the next level with multiple dimensions, allowing them to capture complex relationships.
Tensors allow AI models to learn patterns that are deeply embedded or separated across dimensions but still related (structural conformations of a protein or related words in an article that appear far apart). This ability to model high-dimensional relationships, makes them ideal for representing everything from biological structures in life sciences to language embeddings in LLMs.
Tensors in action: Protein structure example
For example in structural biology, AI models like AlphaFold use 3D tensors to represent spatial relationships between amino acids. These tensors help the model learn how proteins fold, twist, and interact—critical for understanding disease mechanisms and designing therapeutics. This breakthrough wouldn’t be possible without the ability to represent complex spatial data in tensor form and train neural networks to reason over it.
For example, when we embed a protein as a tensor, we’re creating a mathematical representation that preserves crucial information about:
- Sequential data (amino acid order)
- Spatial relationships (how different parts fold and interact)
- Biochemical properties (hydrophobicity, charge, etc.)
This tensor representation makes it possible to apply machine learning and AI techniques to:
- Predict protein folding
- Identify binding sites
- Understand protein-protein interactions
- Discover new drug targets
Check out the image below:
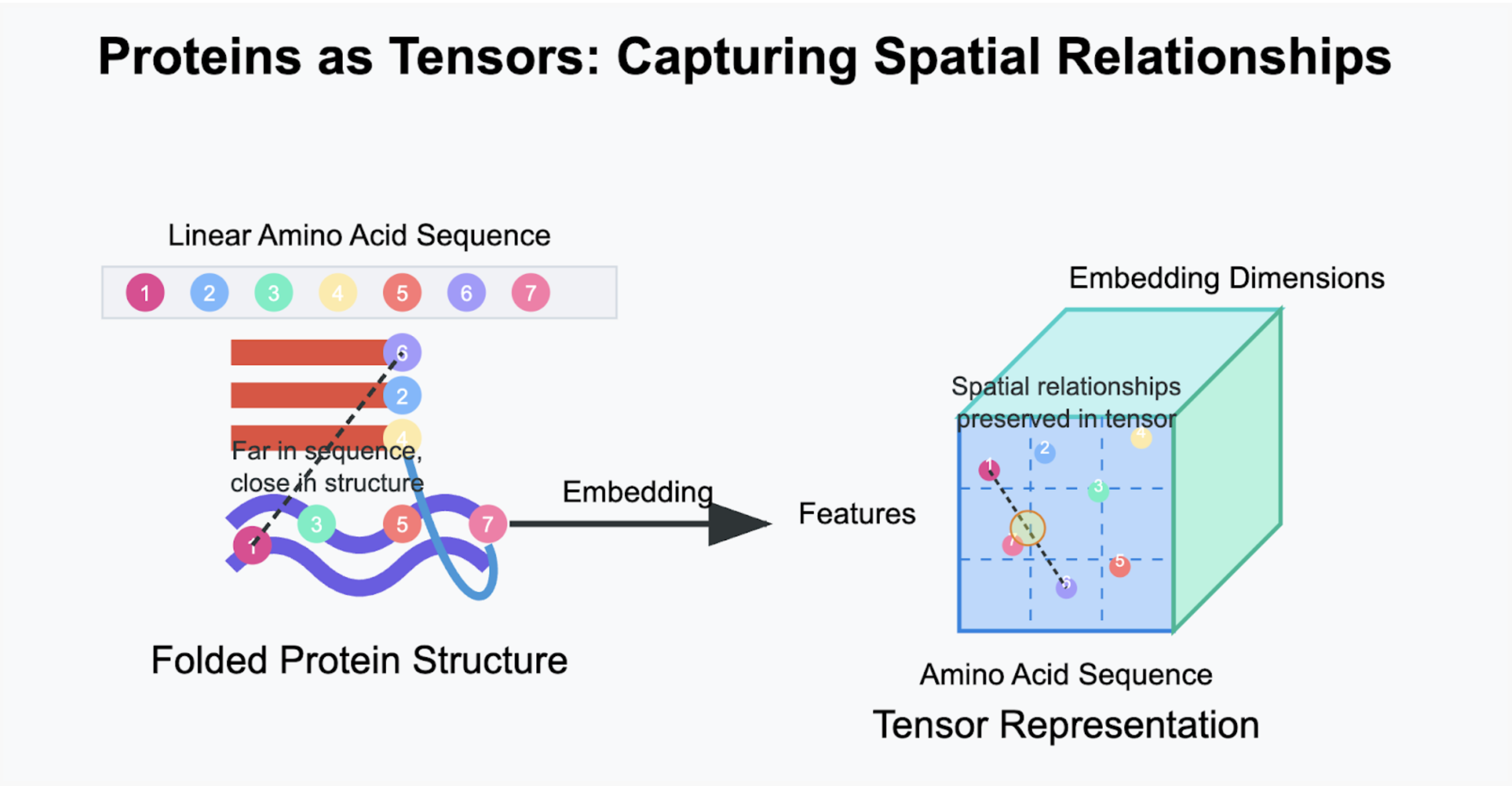
Key Tensor Properties in Protein Analysis: Captures amino acids distant in sequence but close in 3D structure, Preserves critical spatial relationships that determine protein function, Enables ML/AI analysis of protein folding and interactions
In the above figure , we see sequences separated by long distances are structurally similar. We see them embedded as tensors in high dimensional space that encapsulates these relationships well. Now imagine one can create a map of such tensors with not just the embedding but also its associated metadata like the organism, tissue type, pathway information in a store which can then be used for advanced AI use cases based on search & retrieval. It not only accelerates the search across billions of data points to sub seconds but also provides a view to refine the search results with additional metadata to provide precision ranking.
This isn’t limited to proteins. The same principles apply to other domains like medical imaging, where one can encode not just the pixels but also their contextual relevance (crucial for identifying cancer markers where a cell might be obscured by noise), requiring encoding of the surrounding context. It also applies to robotics and IOTs that stream videos with millisecond latency which can be searched for preventive maintenance interventions or sounds that involve medical transcripts & wearables that need real time analytics for instant feedback.
Within life sciences, these possibilities are practically endless.
For more details on medical image embedding read here from my article on visual embeddings from Landing AI.
TL;DR: Life sciences problems are often data-rich but insight-scarce. Tensors allow us to move beyond rows and columns and start thinking in multi-dimensional patterns—across time, space, and biology.
What is next? Setting the stage for advanced applications
Leading companies like Spotify , Yahoo, and Perplexity already leverage Vespa.ai’s tensor capabilities to power their search and recommendation engines at massive scale. Yahoo alone processed 800,000 queries per second and served more than 1 billion users, while Spotify uses Vespa for semantic podcast search with dense retrieval techniques(More on this in the next series).
TL;DR: As we move into the era of agentic AI and multi-step reasoning, the ability to efficiently store, retrieve, and reason over tensor representations becomes even more critical.
In whichever way you define “agents”, what cannot be removed or disqualified is that a good agent will involve “multi step reasoning”. This long reasoning lets LLMs solve complex problems by thinking in many steps. Tensor based retrievals will enable faster multi-step reasoning by reducing latency between retrieval operations and increase accuracy by maintaining context across sequential queries, preserving the chain of thought and allowing for more nuanced relevance ranking based on multiple scientific factors simultaneously.
In Part 2 of this series, I’ll dive deeper into how these capabilities translate into advanced RAG solutions for life sciences by exploring real-world applications that are transforming how pharma teams discover, develop, and deliver treatments. We’ll see how combining tensors with sophisticated search and retrieval mechanisms creates AI systems that aren’t just faster, but fundamentally more capable of understanding the complex relationships inherent in scientific data.
And we will also learn about some of the terms in retrieval systems that make this possible with Vespa.ai like hybrid search, multi phase ranking and structured filtering. Read on and stay curious!

