At 10,000 queries per second with ~30-token queries, you’re pushing ~18 million tokens per minute through your embedding API. At $0.02 per million tokens, that’s over $15,000/month — just for query embeddings. Documents are embedded once. Queries are embedded forever.
What if you could drop that to $0?
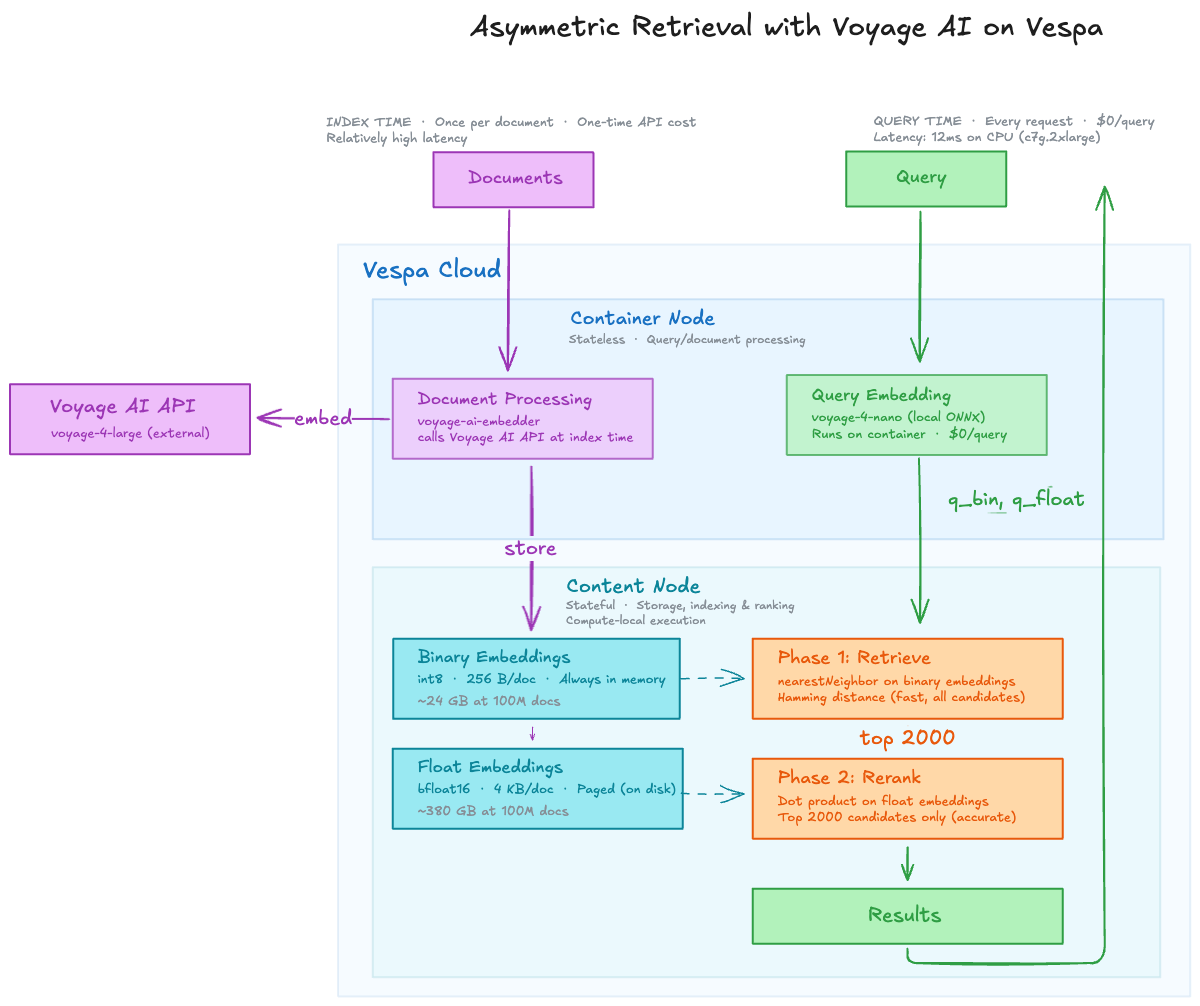
That’s the promise of asymmetric retrieval: embed your documents with the best model money can buy, then embed queries with a tiny model running locally — for free. Voyage AI’s new voyage-4 family is the first to make this practical, and Vespa now has native support for it.
The asymmetric insight
The conventional approach is to use the same embedding model for documents and queries. Same model, same vector space. But it ignores a fundamental asymmetry.
Document embedding is a one-time cost. You embed each document once at indexing time, and it’s not latency-sensitive — whether it takes 10ms or 500ms doesn’t matter because no user is waiting. You can throw the biggest, most accurate model at it and take your time.
Query embedding is the opposite. It’s on the critical path of every single request, continuously, at scale. It needs to be fast, and at 10K QPS the cost dwarfs everything else.
Why use the same model for both?
Asymmetric retrieval splits these two concerns:
- Documents — Embed once with
voyage-4-large. Best accuracy, API-based, no rush. - Queries — Embed continuously with
voyage-4-nano. Tiny, local, free.
This works because all four models in the Voyage 4 family — voyage-4-large, voyage-4, voyage-4-lite, and voyage-4-nano — produce compatible embeddings in a shared vector space.
It also means you can upgrade your query model independently. Start with voyage-4-nano for cost, move to voyage-4-lite for quality — without re-embedding a single document.
The shared embedding space opens up document-side flexibility too. In a multi-tenant system, you could use different models for different tiers — voyage-4-large for premium customers who need the best retrieval quality, voyage-4-lite for cost-sensitive tenants — all searchable with the same query model. Same index, same query path, different quality/cost tradeoffs per tenant.
The numbers
Cost
Let’s be concrete about the 10K QPS scenario:
- 10,000 QPS × 30 tokens = 300,000 tokens/sec
- 300,000 × 60 × 60 × 24 × 30 = ~777 billion tokens/month
- At $0.02/1M tokens ≈ $15,500/month for query embeddings via API
With voyage-4-nano running locally on the Vespa container: $0/month. The model runs as part of the serving infrastructure you’re already paying for.
Latency
API calls add network round-trips. Local inference on voyage-4-nano runs in single-digit milliseconds on CPU.
Quality
Voyage 4 is state-of-the-art. On the RTEB benchmark (29 retrieval datasets, NDCG@10), voyage-4-large beats the competition:
| Comparison | Improvement |
|---|---|
| vs. Gemini Embedding 001 | +3.87% |
| vs. Cohere Embed v4 | +8.20% |
| vs. OpenAI v3 Large | +14.05% |
And asymmetric retrieval — querying with a smaller model against voyage-4-large document embeddings — preserves retrieval quality across medical, code, web, finance, and legal domains.
Storage
Binary quantization gives you a 16x memory reduction over bfloat16 — 2048-dim vectors go from 4,096 bytes to 256 bytes. The full-precision floats are still used for second-phase reranking, paged from disk only when needed. For a deeper dive on quantization tradeoffs, see Embedding Tradeoffs, Quantified.
Why this matters at scale
Cost and quality are table stakes. The real question for large-scale systems is: does this work in production?
Independent scaling
Vespa separates stateless containers (where embedding runs) from content clusters (where data lives). This means you can scale query embedding capacity independently from storage. Need more QPS? Add container nodes. More documents? Add content nodes. They don’t interfere.
No external API on the query path
This is the underrated benefit. With asymmetric retrieval, the query embedding model runs locally inside Vespa — your critical search path has zero dependency on an external API.
That matters when:
- The API goes down. Every embedding API has outages. If your query path depends on one, your search goes down with it.
- You get rate-limited. Traffic spikes don’t care about your API quota. A sudden 3x in query volume means dropped requests — or queued requests that blow your latency budget.
- You need to scale fast. Adding Vespa container nodes takes minutes. Negotiating higher API rate limit may take days. On Vespa Cloud, autoscaling handles traffic spikes automatically — container clusters are stateless and scale up quickly.
Keeping the query path self-contained turns your search system from “works when everything is up” into “works, period.”
Two-phase ranking
Binary vectors are fast — Vespa can do ~1 billion hamming distance calculations per second. But binary quantization loses precision. Vespa’s phased ranking recovers it:
- First phase: Hamming distance on binary embeddings. Fast, cheap, scans the full index.
- Second phase: Float dot-product on the top 2,000 candidates. Accurate, but only touches a bounded set of vectors paged from disk.
This gives you the speed of binary search with the accuracy of full-precision reranking.
Enterprise-proven
This isn’t theoretical. Vespa runs search and recommendation at Spotify, Yahoo, and Perplexity — billions of documents, thousands of QPS, sub-100ms latency. The architecture handles it.
How to set this up
Here’s the complete Vespa configuration for asymmetric retrieval with Voyage AI.
Schema
Two embedding fields — binary for fast retrieval, float for accurate reranking:
schema doc {
document doc {
field id type string {
indexing: summary | attribute
}
field text type string {
indexing: index | summary
}
}
field embedding_float type tensor<bfloat16>(x[2048]) {
indexing: input text | embed voyage-4-large | attribute
attribute {
distance-metric: prenormalized-angular
paged
}
}
field embedding_binary type tensor<int8>(x[256]) {
indexing: input text | embed voyage-4-large | attribute
attribute {
distance-metric: hamming
}
}
}
The paged attribute on embedding_float tells Vespa to keep these vectors on disk, paging them into memory only during second-phase reranking. The binary embeddings stay in memory for fast first-phase retrieval.
Embedders (services.xml)
Two embedders — one API-based for documents, one local for queries:
<container id="default" version="1.0">
<component id="voyage-4-large" type="voyage-ai-embedder">
<model>voyage-4-large</model>
<api-key-secret-ref>apiKey</api-key-secret-ref>
<dimensions>2048</dimensions>
<batching max-size="20" max-delay="20ms"/>
</component>
<component id="voyage-4-nano" type="hugging-face-embedder">
<transformer-model model-id="voyage-4-nano-int8"/>
<tokenizer-model model-id="voyage-4-nano-vocab"/>
<max-tokens>32768</max-tokens>
<pooling-strategy>mean</pooling-strategy>
<normalize>true</normalize>
<prepend>
<query>Represent the query for retrieving supporting documents: </query>
</prepend>
</component>
</container>
The voyage-ai-embedder handles vector quantization automatically — it infers the target precision from the destination tensor type. bfloat16 fields get full-precision embeddings; int8 fields get binary representations.
The hugging-face-embedder runs voyage-4-nano locally. No API calls, no rate limits, no cost. Both model references (voyage-4-nano-int8, voyage-4-nano-vocab) resolve via the Vespa Model Hub.
A note on “quantization” — two different things. The voyage-4-nano-int8 in the model-id refers to model weight quantization: the ONNX model file uses INT8 weights instead of FP32, which makes inference 2-3x faster on CPU with negligible quality loss. This is about how the model itself is stored and executed. The embedder still produces full-precision float vectors as output. Vector quantization is a separate concern — it’s about the precision of the output embeddings you store and search over (bfloat16, int8/binary, etc.). That’s controlled by the tensor type in your schema field, not the model format. These are independent knobs: you can run an INT8-quantized model that outputs float vectors, then store them as binary. For a deeper dive with benchmarks on both, see Embedding Tradeoffs, Quantified.
Rank profile
Two-phase ranking: hamming distance first, float reranking second:
rank-profile binary-with-rerank {
inputs {
query(q_float) tensor<float>(x[2048])
query(q_bin) tensor<int8>(x[256])
}
function binary_closeness() {
expression: 1 - (distance(field, embedding_binary) / 2048)
}
function float_closeness() {
expression: reduce(query(q_float) * attribute(embedding_float), sum, x)
}
first-phase {
expression: binary_closeness
}
second-phase {
expression: float_closeness
rerank-count: 2000
}
}
Querying
Both query tensors are produced by the local voyage-4-nano embedder:
yql=select * from doc where {targetHits: 100}nearestNeighbor(embedding_binary, q_bin)
&ranking=binary-with-rerank
&input.query(q_bin)=embed(voyage-4-nano, "your query here")
&input.query(q_float)=embed(voyage-4-nano, "your query here")
&hits=10
The nearest neighbor search runs on the binary field for speed, while the rank profile handles two-phase scoring.
For a complete runnable example with pyvespa, see the Voyage AI embeddings notebook.
Wrapping up
Asymmetric retrieval makes the most sense when:
- High QPS — The cost savings scale linearly. At 10K QPS, you’re saving $15.5K/month. At 100K QPS, it’s $155K.
- Large corpus — Documents are embedded once, so the large model cost is amortized. The bigger the corpus, the more you benefit from cheap queries.
- Latency-sensitive — Local inference eliminates network round-trips.
When a single model is the better choice:
- Low volume and latency-tolerant — At 10 QPS, the API cost is ~$15/month and the network round-trip doesn’t matter. One model is simpler to operate.
- Quality above all else — Using
voyage-4-largefor both documents and queries gives you the best possible retrieval quality. If you can afford the API cost and latency, symmetric with the top model is hard to beat.
The Voyage 4 family and Vespa’s native integration make asymmetric retrieval practical for the first time. Embed documents with the best model available, query with a tiny local model, and let phased ranking close the quality gap.
Resources:
- Voyage AI embeddings notebook — Full runnable example
- Embedding documentation — Configuring embedders in Vespa
- Binary quantization guide — Deep dive on binarization
- Phased ranking — Multi-phase ranking architecture
- Voyage 4 announcement — Model family details and benchmarks
For those interested in learning more about Vespa, join the Vespa community on Slack to exchange ideas, seek assistance from the community, or stay in the loop on the latest Vespa developments.