Search me if You Can: Building the Next Generation Advanced RAG Solution in Lifesciences
Image generated using OpenAI.
Search is no longer passive — it’s active, ranked, and integral to AI solutions. Without accurate and curated retrieval, Gen AI falls short in regulated, scientific contexts
In Part 1 of this series, we explored how tensors—multi-dimensional data structures—are revolutionizing life sciences by modeling complex biological entities like proteins. We also saw how Vespa.ai’s tensor operations enable powerful search, ranking, and reasoning capabilities essential for life sciences applications.
Its is now the age of RAG, semantic + hybrid search, domain reasoning, powering copilots and AI agents. Lets see how - lets build your next Scientific Search engine!
Beyond LLMs: AI powered Search and Retrieval
When building RAG (Retrieval-Augmented Generation) applications, you’re not just stitching together a chatbot—you’re creating a domain-specific search engine. And that engine must understand far more than text.
Generative AI has pushed the boundaries of AI making search and retrieval an important paradigm for every enterprise. As described prior, when one builds a RAG app, it is more than a RAG, we are building a real Search engine on top of your data. And these are more than text, as the search can represent images, interactions, biological entities and more (read different embeddings in life sciences).
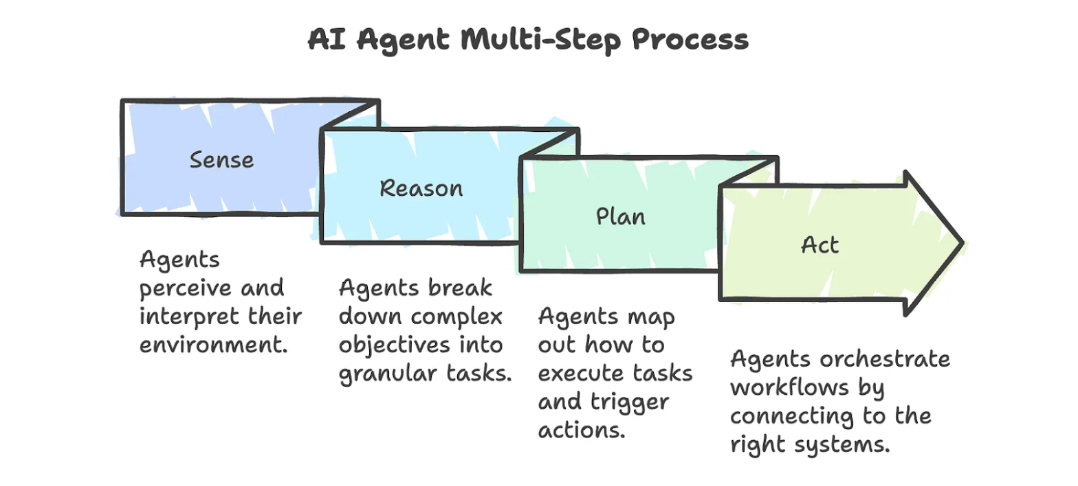
Image Source: FAQ on Demystifying AI Agents
More recently, companies are shifting towards AI agents, and regardless of their specific definition, effective agents must employ multi-step reasoning. This ability to reason through problems in stages allows large language models (LLMs) to tackle complex challenges. However, this approach also introduces new problems: many queries are needed per question, requiring quick turnaround and precision response for each. These are exacerbated in autonomous AI agents, as inaccurate information might be passed on to the next agent in the chain leading to error propagation making hallucinations a serious concern.
Whether it is a RAG app or an autonomous agent, what matters in any search/retrieval is the “accuracy” of the retrieval and “the performance times to make it happen”.
Precision and relevance now make or break AI systems — especially in life sciences
Building your next search engine: relevancy tuning, multiphase ranking and hybrid search - what are they?
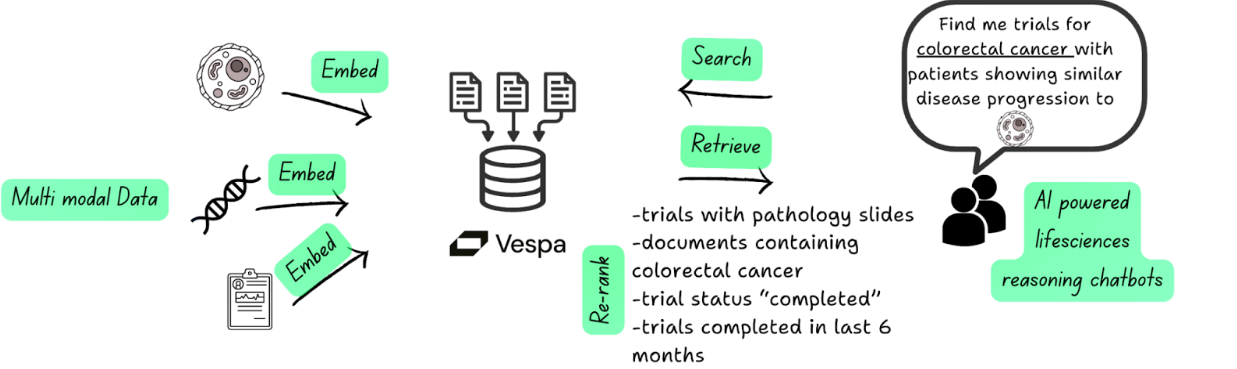
Figure 2: An ideal clinical search solution encompassing multi-modal data queries
Sometime last year when Gen AI was all the rage, we designed a simple clinical trial chatbot. We ran into two challenges that couldn’t be solved natively without doing additional data engineering hacks namely:
- Precision retrieval: how can we find the relevant results from thousands for a specialized indication that is not just based on semantic similarity and
- Custom ranking: how do we rank them in order to ensure the results not just match the direct prompt considerations (indications in this case) but also subtle preferences like trial recency, trial status and co-location to sites from the origin of the user
The relevancy of the studies for the user query was not customizable especially if they were not part of the original prompt but rather were additional signals. What we looked for was an ability to perform relevancy tuning where the most relevant results could be customized based on different attributes.
Most of the vector databases allow for semantic searching by looking for terms similar to the user queries by using Approximate nearest neighbor search (ANN’s). However, achieving high-quality retrieval requires hybrid queries, which combine attribute filtering, lexical search, and ANN search within a single query. Vespa.ai allows you to search, rank, and reason over tensors in real time, bring this power into production—without needing to stitch together multiple systems.
The three main features of Vespa.ai that make it different from a vector database are: Multi vector & tensor support, Hybrid Search and Multi-Phase Ranking. Vespa.ai runs on managed cloud and is on all major CSPs.
Multi-phase ranking: The fuel for search and AI agents
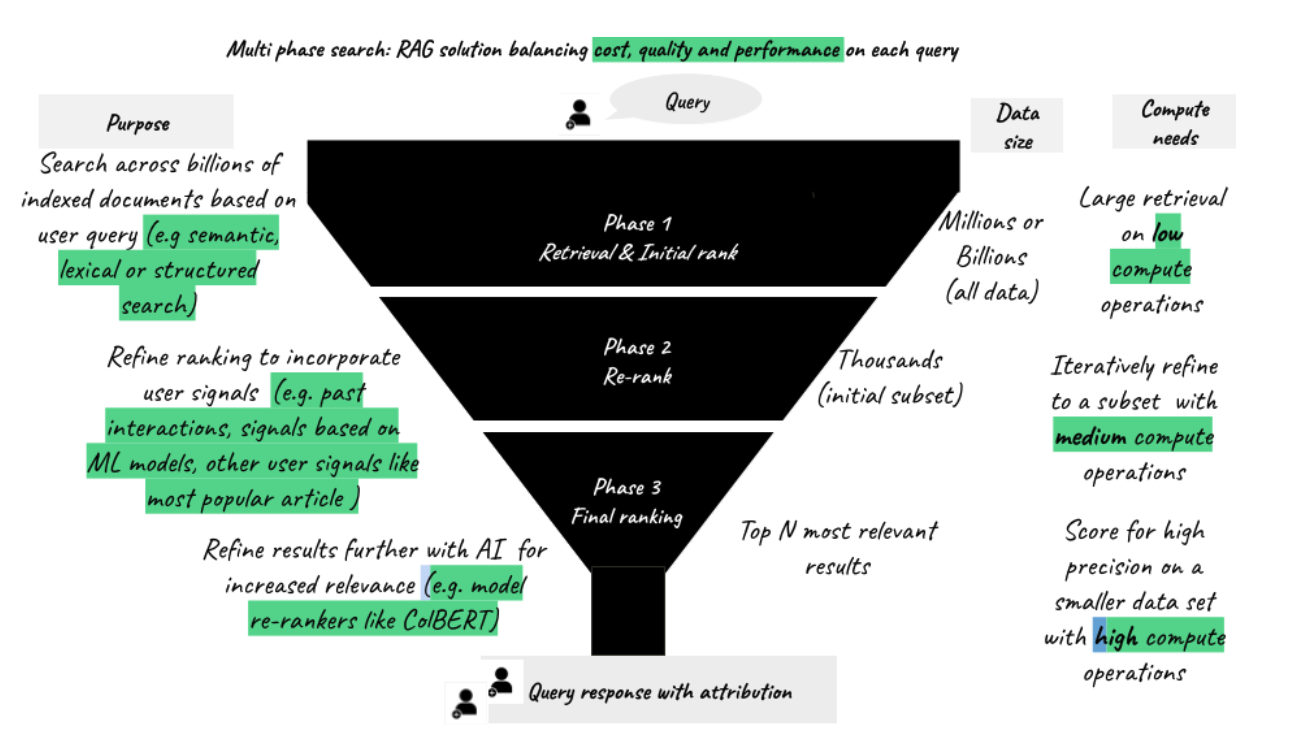
Figure 3: Multi-phase ranking: Perform cheaper, faster, better reasoning for your RAG apps
Multi-phase ranking (also called multi-stage ranking) is a concept used in search engines and AI systems where the process of ranking results is broken into multiple phases or stages, each refining the quality or relevance of results further. Basically:
- Retrieval & initial rank: you start by casting a wider net in retrieving data across all of your “indexed documents” using a vector or hybrid search techniques (Quickly retrieve a broad set of candidates from the index—think millions of documents, molecules, patient profiles, etc matching a specific term)
- Re-rank: One then takes that broad set and apply deeper models to score relevance more intelligently (say only trials matching a certain criteria) and finally
- Final ranking: Finally one reviews that final set to apply additional filter criteria ( any business rules specific to geography or other parameters not part of the original search criteria). A good example of models for re-ranking is in this article.
Rather than fully scoring all your candidates, you’re doing full machine-learned ranking of just the most promising results—smarter and faster.
Multi-phase ranking reduces search costs by focusing most of the compute budget on the most promising candidates. Instead of running expensive, deep-ranking models on every data point, the system first determines the most promising subset of candidates using a lightweight scoring function. Only this smaller set is passed through more advanced models or scoring logic on each data node, significantly cutting down on
Going back to the Clinical chatbot, as seen in the diagram it is useful because when we designed the trial retrieval for authoring we needed to take into account three different things:
- Precision matters more than speed (e.g., patient-trial matching, phase of the trial, any site information that is relevant)
- You want to combine multiple signals (e.g., metadata, semantic embeddings, biomarker relevance)
- You need to enforce clinical or regulatory logic after AI scoring
TL;DR : Mutli-phase ranking increases precision and reduces overall search costs.
Vespa.ai supports multi-phase ranking natively: All of the above steps happen in real time using real-time writeable data, which is a major differentiator when building production-grade AI applications. It also runs in a distributed manner across nodes which brings in the scalability. Vespa.ai can natively scale up and down as needed for the requirements.
This layered approach avoids running heavy computation on irrelevant data and ensures the final results are optimized for precision and business logic
More examples: let’s look at the art of the possible
But the features aren’t just restricted to one area of life sciences. Let’s look at some more examples of the questions that we can answer across the value chain and how it relates to the features we have talked earlier.
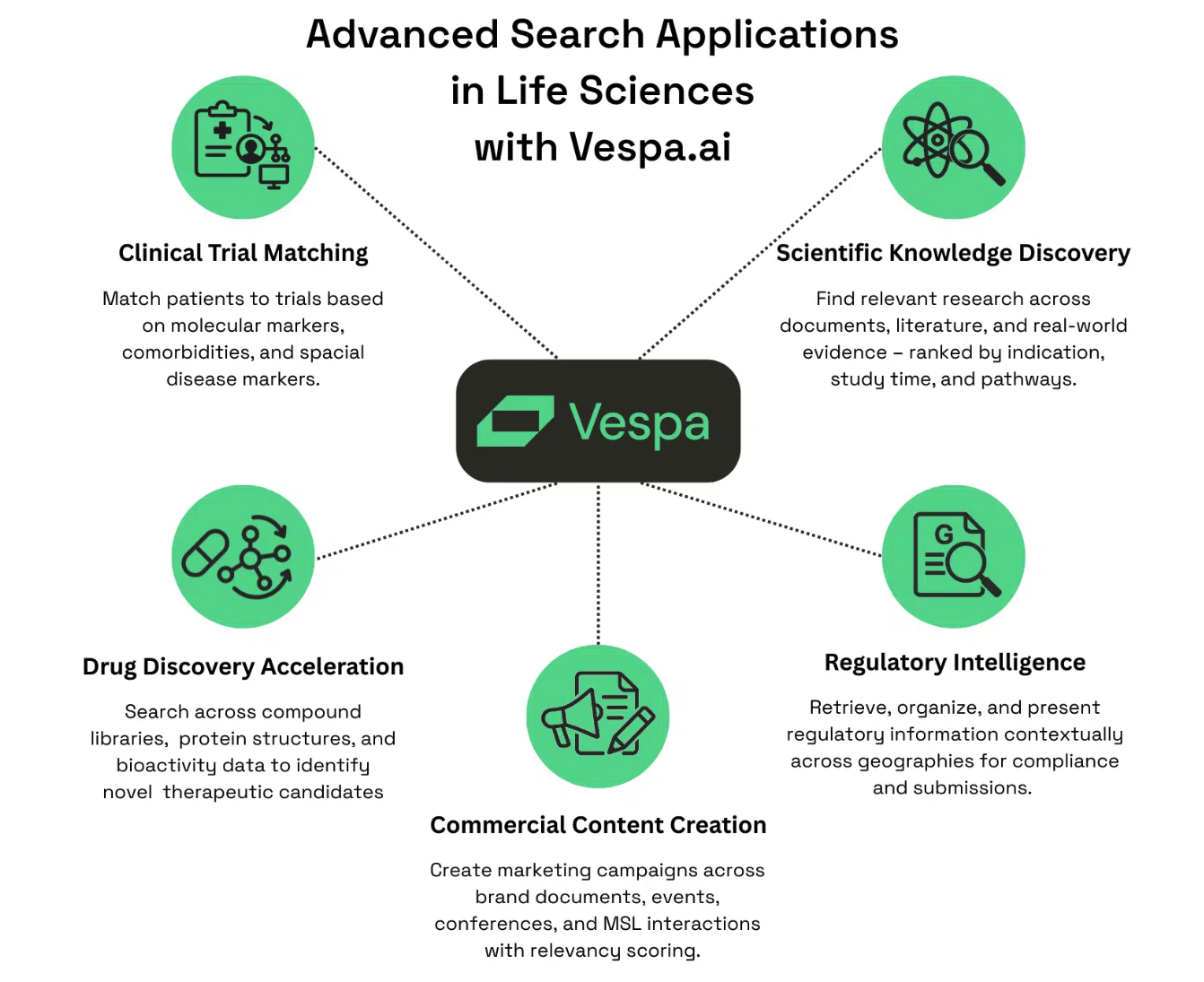
1. Hybrid search (lexical & Text search) → Improve Precision
What does it do?
- Combines vector-based similarity with keyword matching to deliver results that are both semantically & lexically relevant and precision-focused.
What questions?
“Can we power patient-specific evidence engines that bring back trial results tailored to specific molecular markers or comorbidities?“
“How can a researcher quickly find similar compounds—by structure, function, or literature co-occurrence—all in one query?“
2. Multi vector /Tensor support → Provide speed across multi modal data
What does it do?
- Handles real-time queries across large, multi modal datasets—perfect for environments like drug discovery, clinical trials, or scientific research where data is multi modal and a tensor could be beneficial
What questions?
“How do you surface the right insights from thousands of internal PDFs, scientific papers, and LLM outputs—in real time?”
“Can you combine medical image embeddings, metadata about them, and user defined prompts without building 5 separate pipelines and still retrieve relevant results?”
3. Custom (multi phase) ranking allows → Increase Result Relevancy & reduce infra costs
What does it do?
- Optimizes accuracy and relevance by refining search results based on custom ranking that can be user defined.
What questions?
“Can a clinical LLM powered chatbot contextually rank results based on disease synonyms, trial phase, patient cohort, and tissue type at the same?”
“Enables search and discovery tools to adapt to patient profiles, research questions, or therapeutic targets, so relevance isn’t one-size-fits-all.”
Who uses Vespa.ai today?
Vespa.ai is used by some of the popular web scale platforms like Spotify, Perplexity and Yahoo. Yahoo crunched hundred thousands of queries per second and served more than 1 billion users and they leverage Vespa.ai for selecting and serving all the content on their yahoo.com (e. Home Page, Finance, Ad Network etc). The main differentiator they get from Vespa.ai is the ability to query by personalized profile score using machine-learned models.
Spotify leverages Vespa.ai for a variety of use cases and one of the critical ones is to provide semantic search in Podcasts. The system uses a machine learning method called Dense Retrieval, where both user queries and content—such as podcast episodes—are encoded into a shared vector space. By placing related content and queries close together in this space, the model enables efficient and semantic search, retrieving results based on meaning rather than exact keyword matches.
Perplexity.ai’s conversational search engine, boasting 10 million active weekly users, has indexed the web into billion scale document index to deliver sources for its responses. To ensure scalability and real-time performance for high query volumes, Perplexity utilizes the Vespa.ai platform as a robust foundation for its web-scale RAG AI application.
The commonality between all these is the need for highly precise search, and powerful custom ranking that can produce high precision at large scales
The future: where are we heading?
The future of AI in life sciences isn’t just about generating text or making predictions—it’s about creating systems that can navigate the complex terrain of multi modal scientific data with the nuance and precision that modern healthcare demands. In short, building advanced RAG solutions for life sciences requires more than just storing vectors—it demands a system that brings together search, retrieval, ranking, inference, and scalability cohesively while keeping costs down. Tensor databases like Vespa.ai don’t just store high-dimensional data; they enable you to reason over it in ways that reflect the complex, interconnected nature of life sciences data across the value chain.
In life sciences, precision matters deeply — whether it’s finding the right protocol, molecule, or evidence. For example, when searching for clinical trials, relevance isn’t just semantic similarity. It’s trial phase, recency, indication match, site proximity, and regulatory status.
For life sciences, this means AI-driven search that doesn’t just return possible matches — it returns the right information, at the right time, tailored to scientific and clinical workflows. This reduces noise, improves trust, and accelerates decision-making where accuracy is non-negotiable.
Hopefully this becomes the inspiration for your own journey to build a state of the art search engine RAG on your data